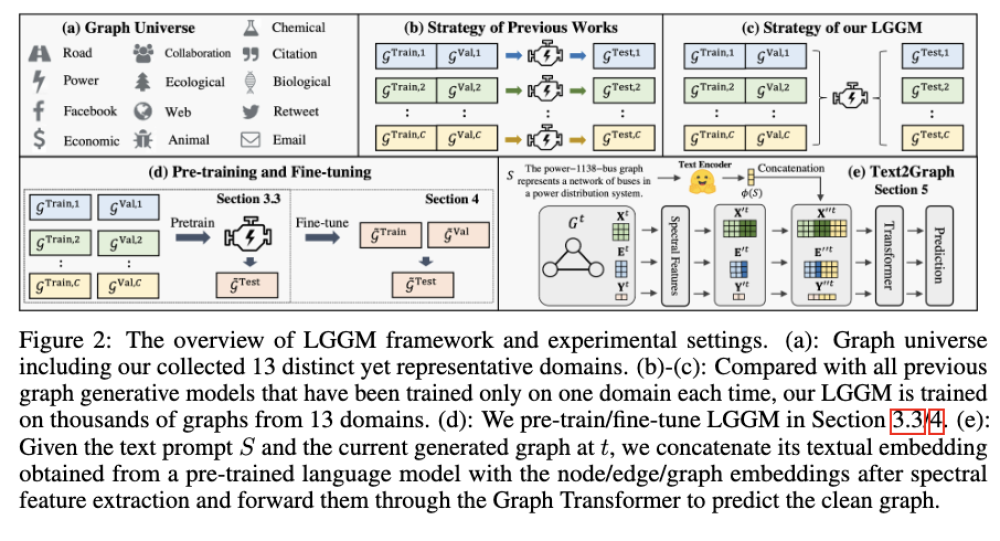
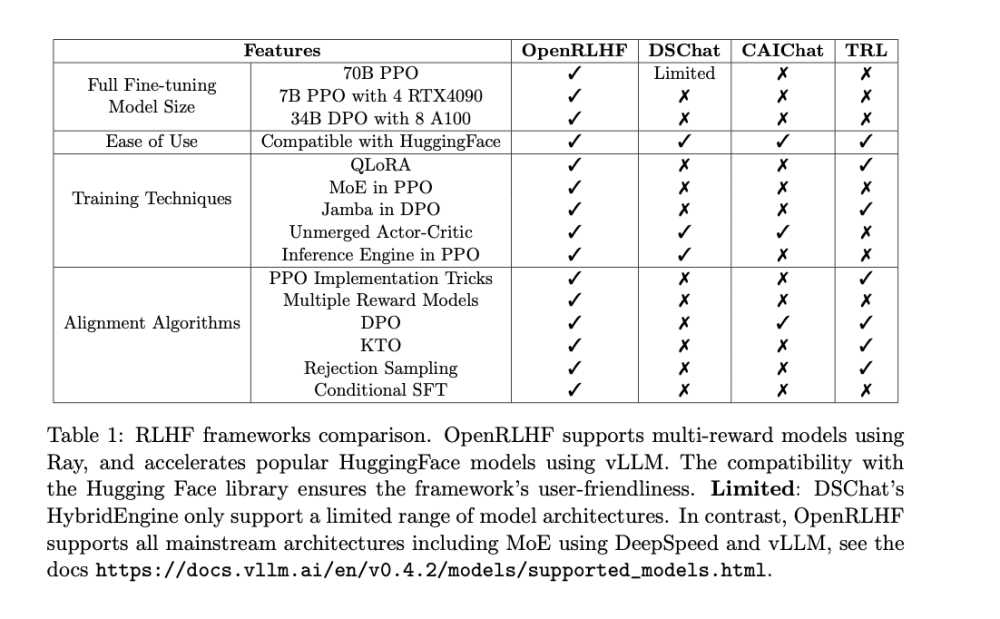
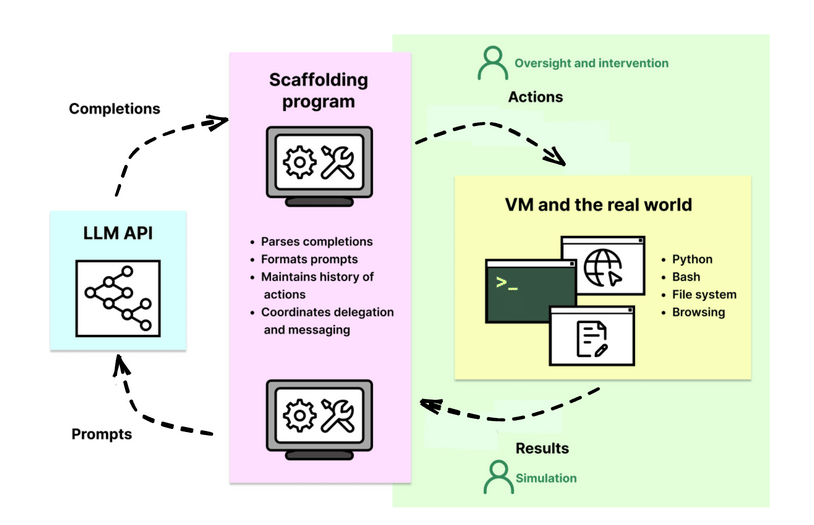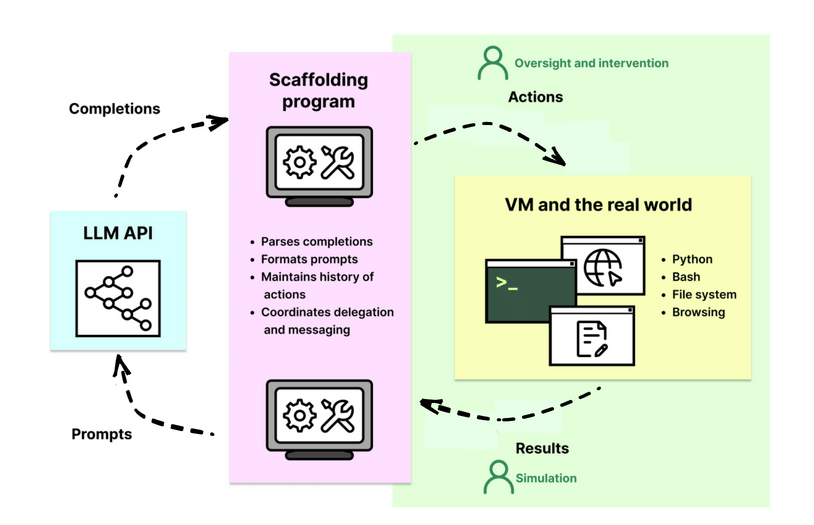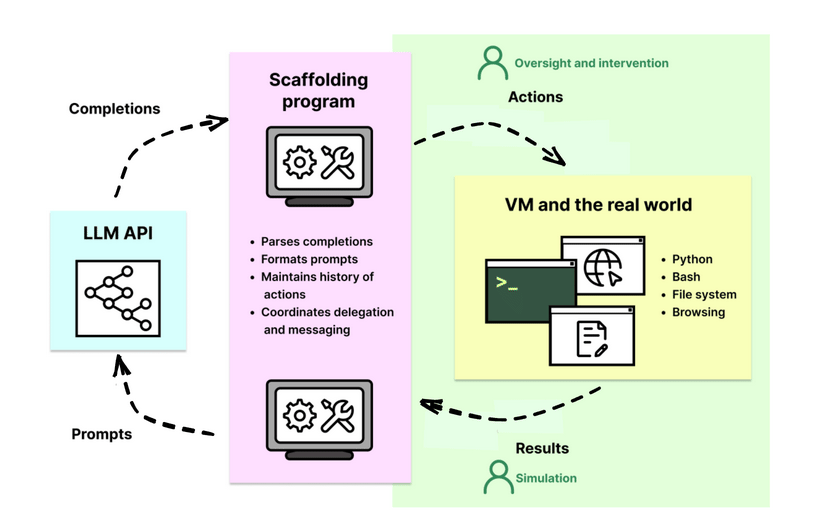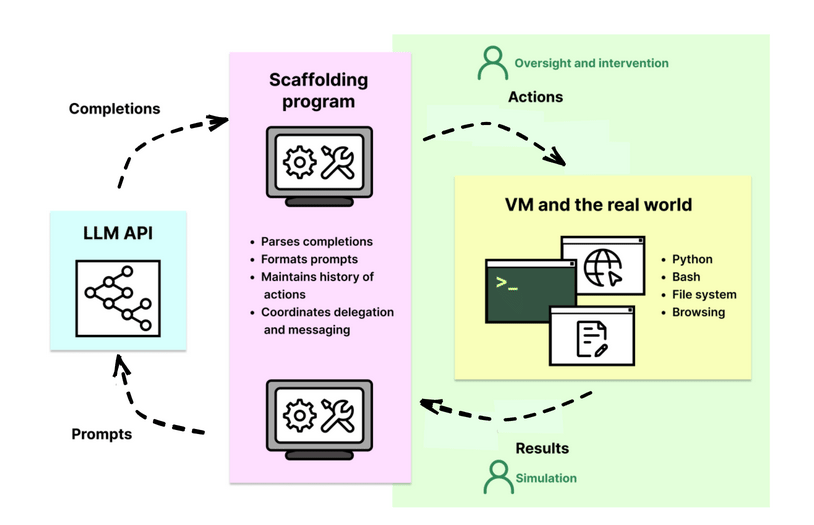
Cuộc đua AI suy luận bùng nổ: OpenAI vượt mặt Google với model o3 mạnh gấp 3 lần o1
- OpenAI vừa công bố phiên bản nâng cấp của model AI thông minh nhất của công ty, chỉ một ngày sau khi Google ra mắt model suy luận đầu tiên
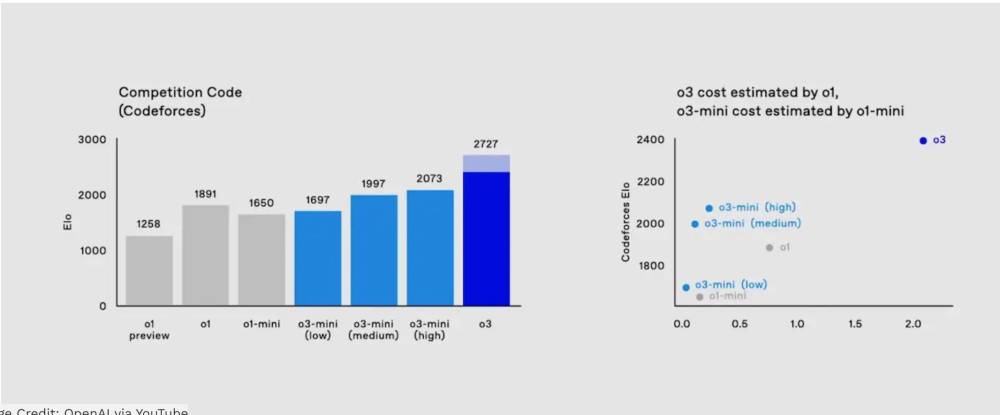
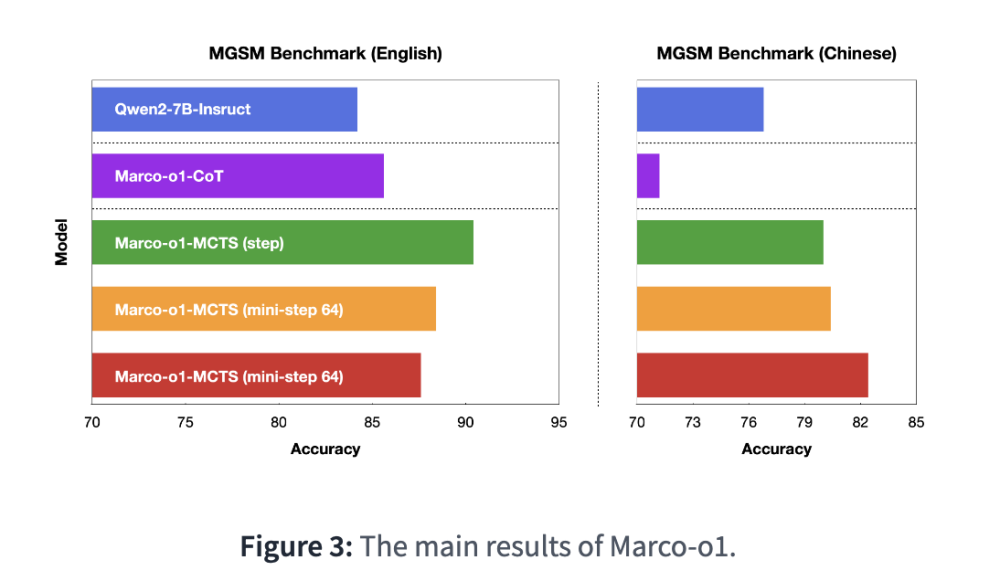
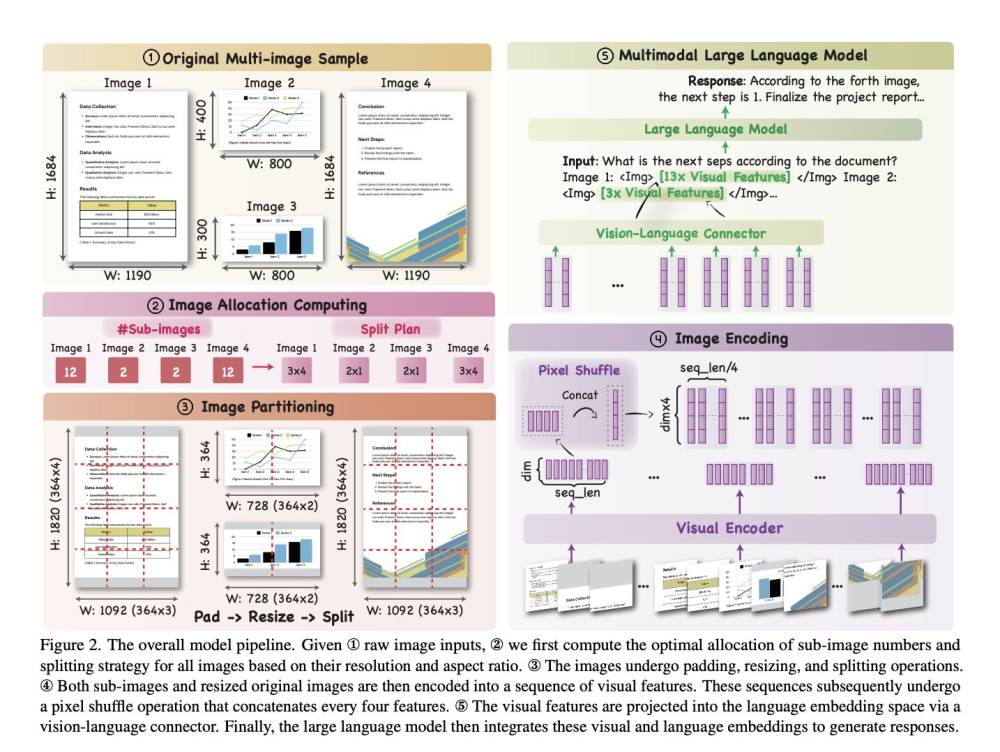
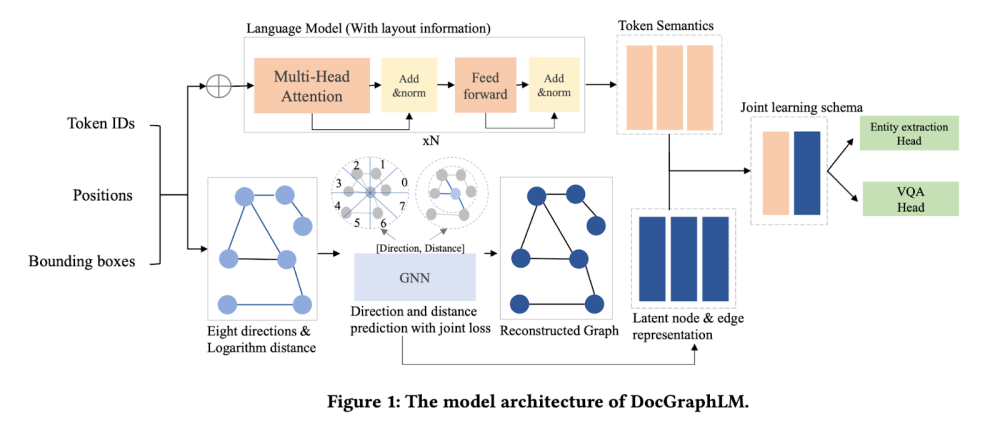
- Model mới có tên o3, thay thế cho o1 được giới thiệu từ tháng 9/2024. Model này có khả năng suy nghĩ kỹ hơn trước khi đưa ra câu trả lời
- Theo CEO Sam Altman, đây là bước khởi đầu cho giai đoạn tiếp theo của AI, khi các model có thể thực hiện các tác vụ phức tạp đòi hỏi nhiều suy luận
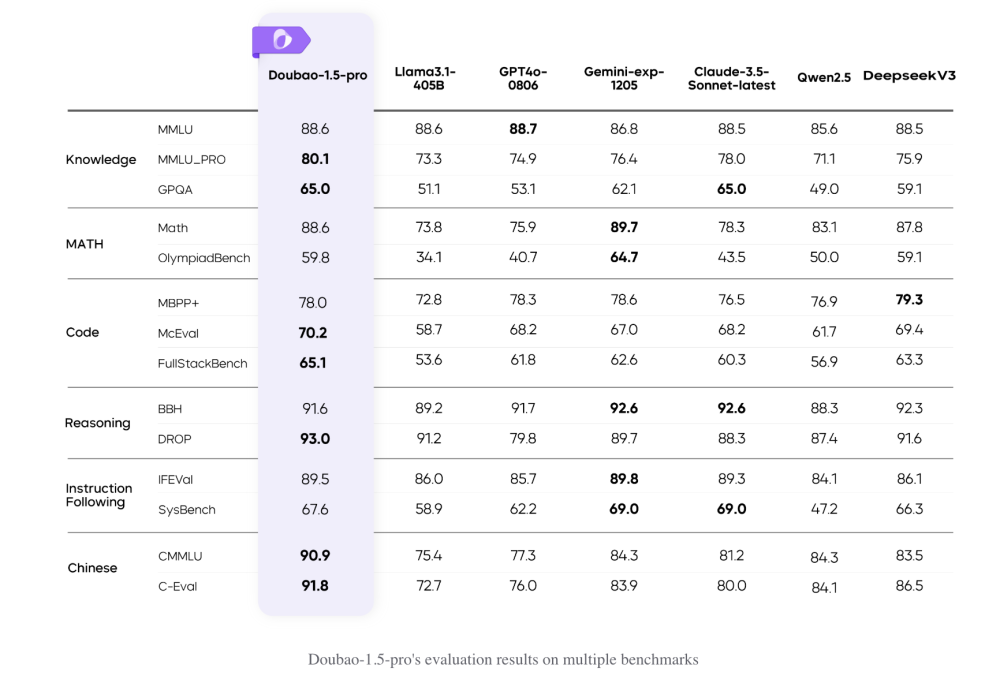
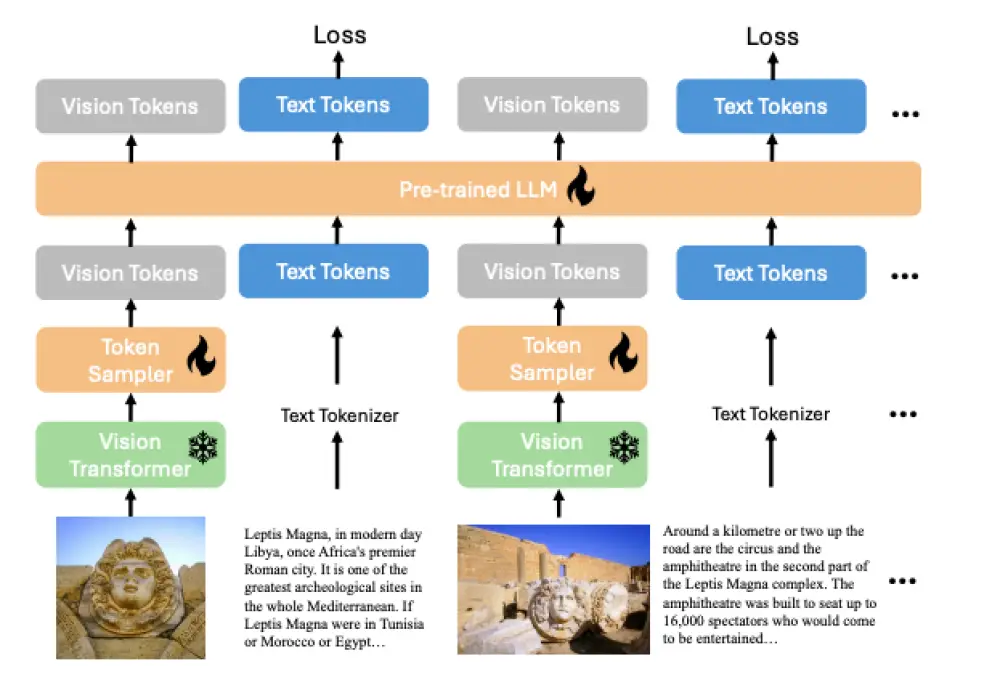
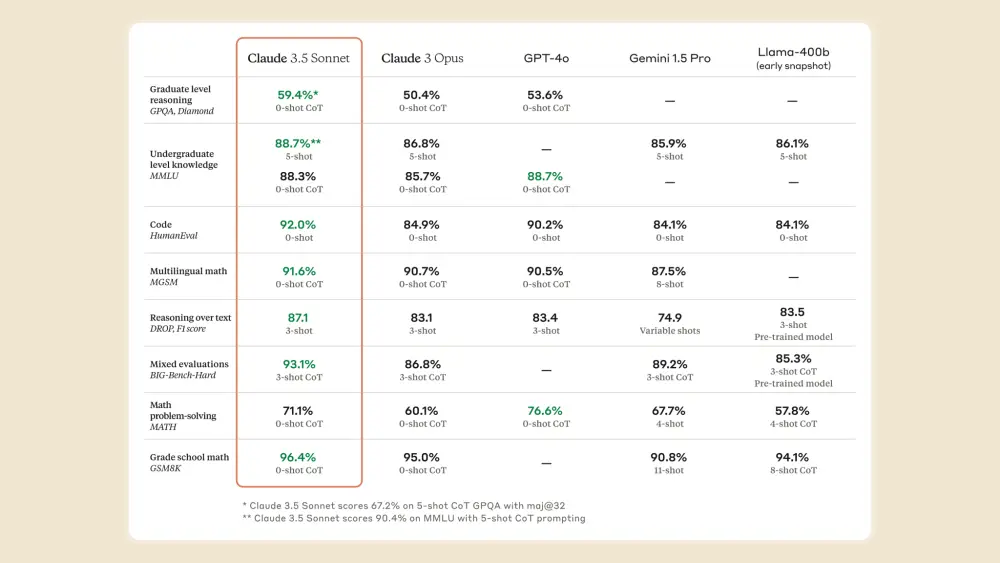
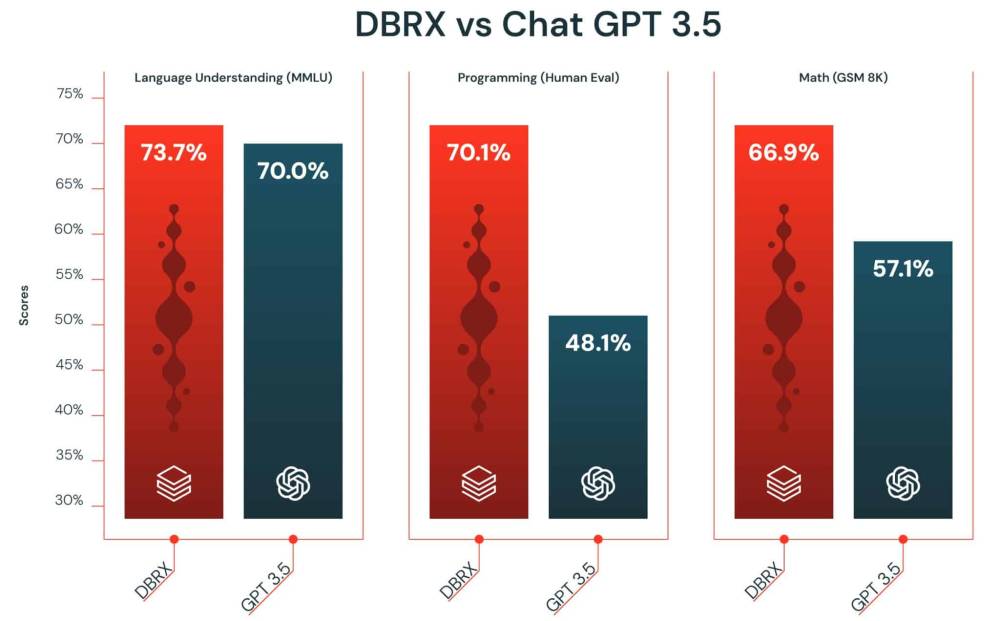
- o3 đạt điểm cao hơn đáng kể so với phiên bản trước trong nhiều tiêu chí:
+ Kỹ năng lập trình phức tạp
+ Năng lực toán học và khoa học nâng cao
+ Khả năng giải quyết các bài toán khó về logic gấp 3 lần so với o1
- Google cũng vừa công bố model Gemini 2.0 Flash Thinking, nhưng o3 của OpenAI vượt trội hơn 20% trong các bài kiểm tra về khả năng agent
- OpenAI phát triển 2 phiên bản: o3 và o3-mini, nhưng chưa công bố rộng rãi mà sẽ mời người dùng bên ngoài đăng ký thử nghiệm
- Công ty cũng tiết lộ phương pháp "deliberative alignment" (“điều chỉnh thông qua cân nhắc”)giúp model an toàn hơn bằng cách tự suy xét về các yêu cầu và câu trả lời
- Cuối năm 2024 chứng kiến nhiều thông báo quan trọng từ các ông lớn công nghệ:
+ Google ra mắt Gemini 2.0
+ OpenAI giới thiệu model tạo video mới
+ Ra mắt phiên bản miễn phí ChatGPT search
+ Cung cấp dịch vụ ChatGPT qua điện thoại
📌 OpenAI tăng tốc cuộc đua AI suy luận với model o3 mạnh gấp 3 lần o1, vượt trội 20% so với Gemini 2.0 của Google. Model mới tích hợp công nghệ deliberative alignment cho độ an toàn cao và sẽ được thử nghiệm giới hạn trước khi ra mắt chính thức.
https://www.wired.com/story/openai-o3-reasoning-model-google-gemini/
OpenAI nâng cấp mô hình AI thông minh nhất với kỹ năng lập luận cải thiện
Một ngày sau khi Google công bố mô hình đầu tiên có khả năng lập luận vấn đề, OpenAI đã nâng tầm cuộc chơi với phiên bản cải tiến của chính mình.
OpenAI hôm nay công bố phiên bản cải tiến của mô hình trí tuệ nhân tạo mạnh mẽ nhất của mình cho đến nay—một mô hình dành nhiều thời gian hơn để cân nhắc câu hỏi—chỉ một ngày sau khi Google giới thiệu mô hình đầu tiên thuộc loại này.
Mô hình mới của OpenAI, mang tên o3, thay thế o1, được công ty ra mắt vào tháng 9. Tương tự như o1, mô hình mới dành thời gian suy ngẫm về vấn đề để đưa ra câu trả lời tốt hơn cho những câu hỏi đòi hỏi lập luận logic từng bước. (OpenAI bỏ qua tên gọi “o2” vì đây là tên của một nhà mạng di động tại Anh.)
“Đây là khởi đầu cho giai đoạn tiếp theo của AI,” CEO OpenAI Sam Altman phát biểu trong buổi livestream hôm thứ Sáu. “Mô hình này cho phép thực hiện các nhiệm vụ ngày càng phức tạp đòi hỏi nhiều lập luận.”
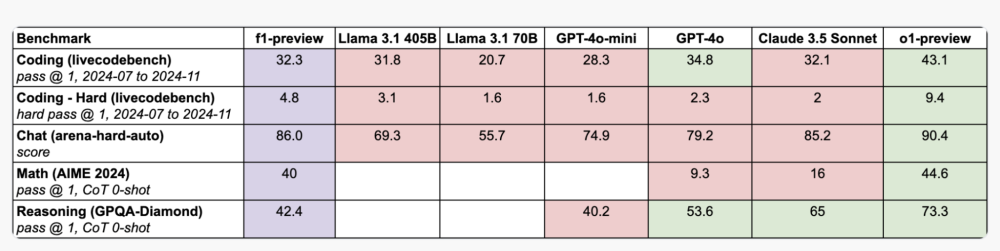
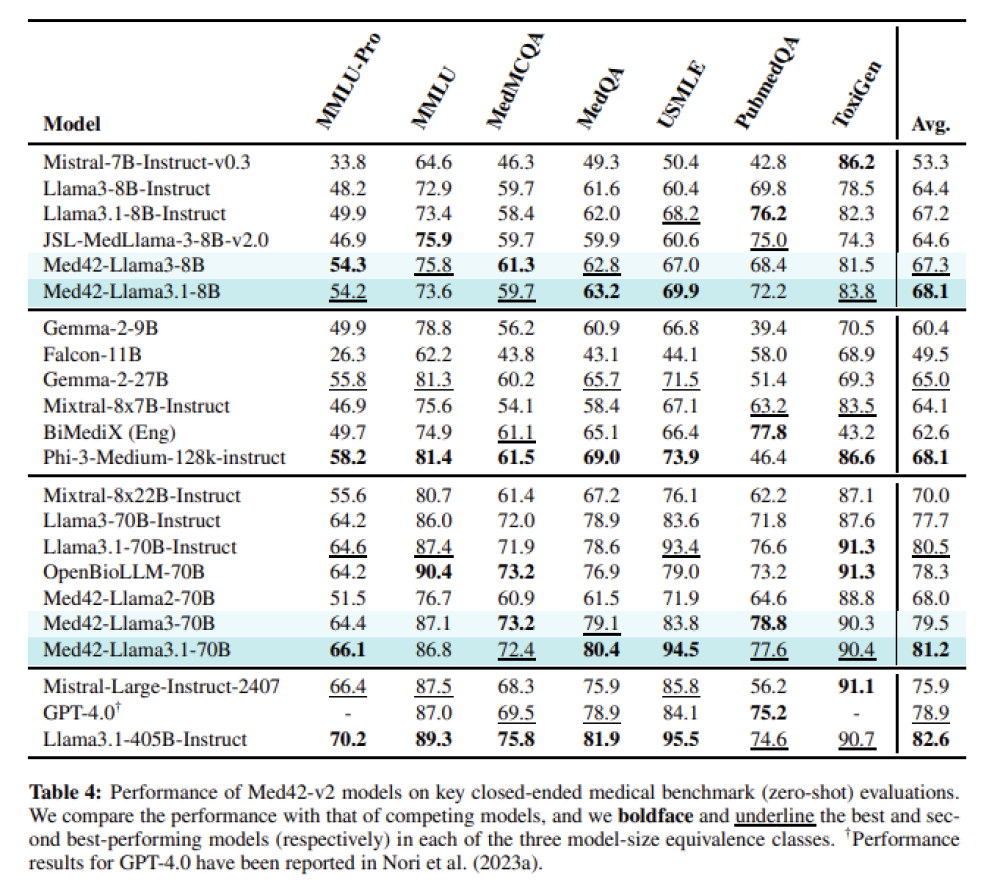
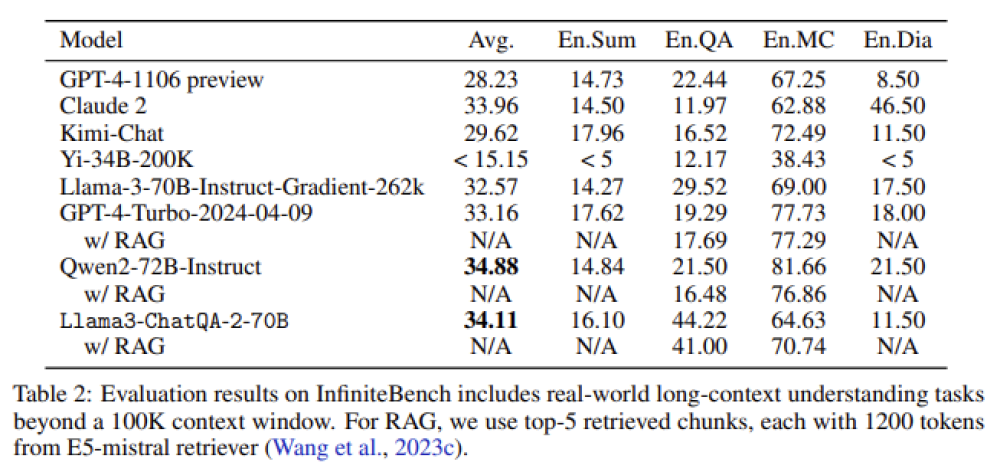
Mô hình o3 đạt điểm cao hơn nhiều trên một số tiêu chí so với phiên bản tiền nhiệm, OpenAI cho biết, bao gồm khả năng lập trình phức tạp và năng lực toán học, khoa học nâng cao. Nó vượt trội gấp ba lần so với o1 trong việc trả lời các câu hỏi từ ARC-AGI, một tiêu chuẩn đánh giá khả năng lập luận của mô hình AI đối với các vấn đề toán học và logic cực kỳ khó mà lần đầu tiên chúng gặp phải.
Google cũng đang theo đuổi hướng nghiên cứu tương tự. Hôm qua, nhà nghiên cứu Google Noam Shazeer tiết lộ trên X rằng công ty đã phát triển mô hình lập luận riêng, mang tên Gemini 2.0 Flash Thinking. CEO Sundar Pichai của Google gọi đây là “mô hình cẩn trọng nhất của chúng tôi” trong bài đăng của mình. Mô hình mới của Google đạt điểm cao trên SWE-Bench, một bài kiểm tra đánh giá khả năng tác nghiệp của các mô hình AI.
Tuy nhiên, mô hình o3 của OpenAI vẫn tốt hơn o1 đến 20%. “o3 đã vượt xa kỳ vọng,” Ofir Press, nhà nghiên cứu sau tiến sĩ tại Đại học Princeton, người giúp phát triển SWE-Bench, nhận xét. “Sự cải tiến này rất bất ngờ, tôi không rõ họ đã làm thế nào.”
Sự cạnh tranh giữa OpenAI và Google ngày càng khốc liệt. Điều này rất quan trọng đối với OpenAI trong việc thu hút thêm đầu tư và xây dựng một doanh nghiệp có lợi nhuận. Trong khi đó, Google cố gắng chứng minh rằng họ vẫn đứng đầu về nghiên cứu AI.
Những mô hình mới này cũng cho thấy các công ty AI ngày càng tập trung vào việc tối ưu hóa thay vì chỉ tăng kích thước mô hình để đạt được trí thông minh cao hơn.
OpenAI cho biết có hai phiên bản của mô hình mới: o3 và o3-mini. Công ty hiện chưa cung cấp mô hình này cho công chúng mà chỉ mời các đối tác bên ngoài đăng ký thử nghiệm.
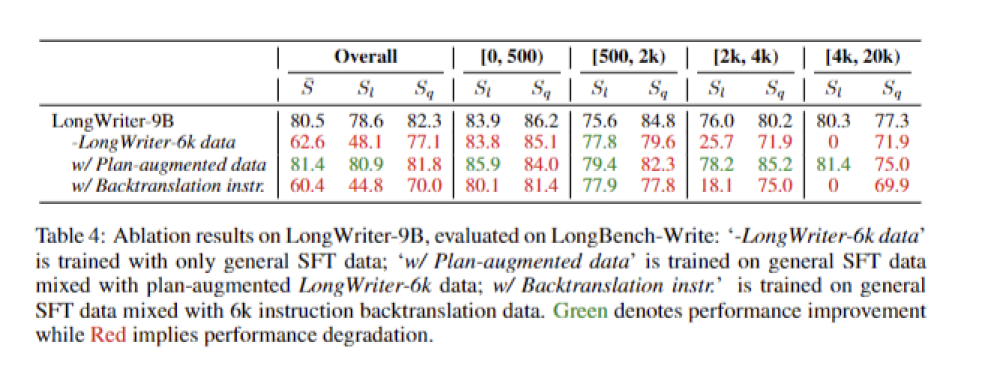
OpenAI hôm nay cũng tiết lộ chi tiết về kỹ thuật sử dụng để điều chỉnh o1. Phương pháp mới, gọi là “điều chỉnh thông qua cân nhắc” (deliberative alignment), liên quan đến việc đào tạo mô hình với một bộ quy chuẩn an toàn, yêu cầu mô hình lập luận về bản chất của yêu cầu cũng như câu trả lời của chính nó để kiểm tra xem có vi phạm các quy chuẩn này hay không. Cách tiếp cận này khiến mô hình khó bị lừa vào các hành vi sai lệch hơn vì quá trình lập luận của nó có thể phát hiện các ý đồ không phù hợp.
Các mô hình ngôn ngữ lớn có thể trả lời nhiều câu hỏi rất tốt, nhưng thường gặp khó khăn khi giải quyết các câu đố đòi hỏi toán học hoặc logic cơ bản. OpenAI o1 tích hợp đào tạo giải quyết vấn đề từng bước, giúp mô hình AI xử lý tốt hơn các vấn đề này.
Những mô hình có khả năng lập luận sẽ quan trọng khi các công ty triển khai “tác nhân AI” (AI agents) có thể giải quyết vấn đề phức tạp một cách đáng tin cậy thay mặt người dùng.
“Điều này thực sự đánh dấu việc chúng ta đang tiến đến biên giới mới về tính hữu ích,” Mark Chen, phó chủ tịch cấp cao về nghiên cứu tại OpenAI, phát biểu trong buổi livestream hôm nay.
“Mô hình này rất xuất sắc trong lập trình,” Altman bổ sung.
Mặc dù một bước đột phá thực sự vẫn chưa xuất hiện vào cuối năm nay, nhưng tốc độ công bố công nghệ AI gần đây thật đáng kinh ngạc.
Đầu tháng này, Google đã công bố phiên bản mới của mô hình chủ lực mang tên Gemini 2.0, trình diễn khả năng hỗ trợ duyệt web và làm trợ lý thông qua điện thoại thông minh hoặc kính thông minh.
OpenAI gần đây cũng đã công bố hàng loạt cải tiến, bao gồm một phiên bản mới của mô hình tạo video, phiên bản miễn phí của công cụ tìm kiếm tích hợp ChatGPT, và cách truy cập ChatGPT qua điện thoại bằng cách gọi 1-800-ChatGPT.
OpenAI Upgrades Its Smartest AI Model With Improved Reasoning Skills
A day after Google announced its first model capable of reasoning over problems, OpenAI has upped the stakes with an improved version of its own.
NEW YORK NEW YORK DECEMBER 04 OpenAI CEO Sam Altman Visits Making Money With Charles Payne at Fox Business Network...
OpenAI CEO Sam Altman Visits "Making Money With Charles Payne" at Fox Business Network Studios on December 04, 2024 in New York City.Photograph: Mike Coppola/Getty Images
OpenAI today announced an improved version of its most capable artificial intelligence model to date—one that takes even more time to deliberate over questions—just a day after Google announced its first model of this type.
OpenAI’s new model, called o3, replaces o1, which the company introduced in September. Like o1, the new model spends time ruminating over a problem in order to deliver better answers to questions that require step-by-step logical reasoning. (OpenAI chose to skip the “o2” moniker because it's already the name of a mobile carrier in the UK.)
AI Lab Newsletter by Will Knight
WIRED’s resident AI expert Will Knight takes you to the cutting edge of this fast-changing field and beyond—keeping you informed about where AI and technology are headed. Delivered on Wednesdays.
Sign up
By signing up, you agree to our user agreement (including class action waiver and arbitration provisions), and acknowledge our privacy policy.
“We view this as the beginning of the next phase of AI,” said OpenAI CEO Sam Altman on a livestream Friday. “Where you can use these models to do increasingly complex tasks that require a lot of reasoning.”
Featured Video
Historian Answers Samurai Questions
The o3 model scores much higher on several measures than its predecessor, OpenAI says, including ones that measure complex coding-related skills and advanced math and science competency. It is three times better than o1 at answering questions posed by ARC-AGI, a benchmark designed to test an AI models’ ability to reason over extremely difficult mathematical and logic problems they’re encountering for the first time.
Google is pursuing a similar line of research. Noam Shazeer, a Google researcher, yesterday revealed in a post on X that the company has developed its own reasoning model, called Gemini 2.0 Flash Thinking. Google’s CEO, Sundar Pichai, called it “our most thoughtful model yet” in his own post. Google’s new model achieved a high score on SWE-Bench, a test that measures a models’ agentic abilities.
However, OpenAI’s new o3 model is 20 percent better than o1. “o3 blew it out of the water,” says Ofir Press, a post-doctoral researcher at Princeton University who helped develop SWE-Bench. “Very surprising increase, not sure how they did it.”
The two dueling models show competition between OpenAI and Google to be fiercer than ever. It is crucial for OpenAI to demonstrate that it can keep making advances as it seeks to attract more investment and build a profitable business. Google is meanwhile desperate to show that it remains at the forefront of AI research.
The new models also show how AI companies are increasingly looking beyond simply scaling up AI models in order to wring greater intelligence out of them.
Most Popular
The Best Cookbooks of 2024
Kitchen
The Best Cookbooks of 2024
By Joe Ray
The Best Hair Straighteners to Iron Out Those Kinks
Lifestyle
The Best Hair Straighteners to Iron Out Those Kinks
By Kat Merck
Give Your Back a Break With Our Favorite Office Chairs
Buying Guides
Give Your Back a Break With Our Favorite Office Chairs
By Julian Chokkattu
The Latest Indiana Jones Game Showcases Indy's Swashbuckling Charm
Culture
The Latest Indiana Jones Game Showcases Indy's Swashbuckling Charm
By Matt Kamen
Advertisement
OpenAI says there are two versions of the new model, o3 and o3-mini. The company is not making the models publicly available yet but says it will invite outsiders to apply to perform testing of them.
OpenAI today also revealed more details of techniques used to align o1. The new method, known as deliberative alignment, involves training a model with a set of safety specifications and having it reason about the nature of the request as well as its own answer it is given to interrogate whether it may contravene its guardrails. The approach makes the model more difficult to trick into misbehavior because its reasoning process can root out attempts at mischief.
Large language models can answer many questions remarkably well, but they often stumble when asked to solve puzzles that require basic math or logic. OpenAI’s o1 incorporates training on step-by-step problem-solving that makes an AI model better able to tackle these types of problems.
Models that reason over problems will also be important as companies seek to deploy so-called AI agents that can reliably figure out how to solve complex problems on a users’ behalf.
“This really signifies that we are really climbing the frontier of utility,” Mark Chen, senior vice president of research at OpenAI said on today’s livestream.
“This model is incredible at programming,” Atlman added.
While a true breakthrough moment has eluded tech giants at the end of the year, the pace of AI announcements has been dizzying of late.
Early this month Google announced a new version of its flagship model, called Gemini 2.0, and demonstrated it as a web browsing helper and as an assistant that sees the world through a smartphone or a pair of smart glasses.
OpenAI has made numerous announcements in the run up to Christmas, including a new version of its video-generating model, a free version of its ChatGPT-powered search engine, and a way to access ChatGPT over the phone by calling 1-800-ChatGPT.