LLaVA-o1 của Trung Quốc thách thức OpenAI o1 với khả năng suy luận vượt trội
- Các nhà nghiên cứu Trung Quốc vừa công bố mô hình LLaVA-o1, một mô hình nguồn mở cạnh tranh với OpenAI o1, tập trung vào việc cải thiện khả năng suy luận của mô hình ngôn ngữ thị giác (VLM).
- Mô hình này giải quyết các hạn chế của VLM truyền thống bằng cách:
+ Thực hiện suy luận có cấu trúc qua 4 giai đoạn: tóm tắt, chú thích, suy luận và kết luận
+ Chỉ hiển thị giai đoạn kết luận cho người dùng
+ Áp dụng kỹ thuật tìm kiếm theo cấp độ để tạo và chọn lọc kết quả tối ưu ở mỗi giai đoạn
- Quá trình đào tạo bao gồm:
+ Sử dụng bộ dữ liệu 100.000 cặp hình ảnh-câu hỏi-câu trả lời
+ GPT-4o tạo quy trình suy luận chi tiết 4 giai đoạn
+ Fine-tune trên nền tảng Llama-3.2-11B-Vision-Instruct
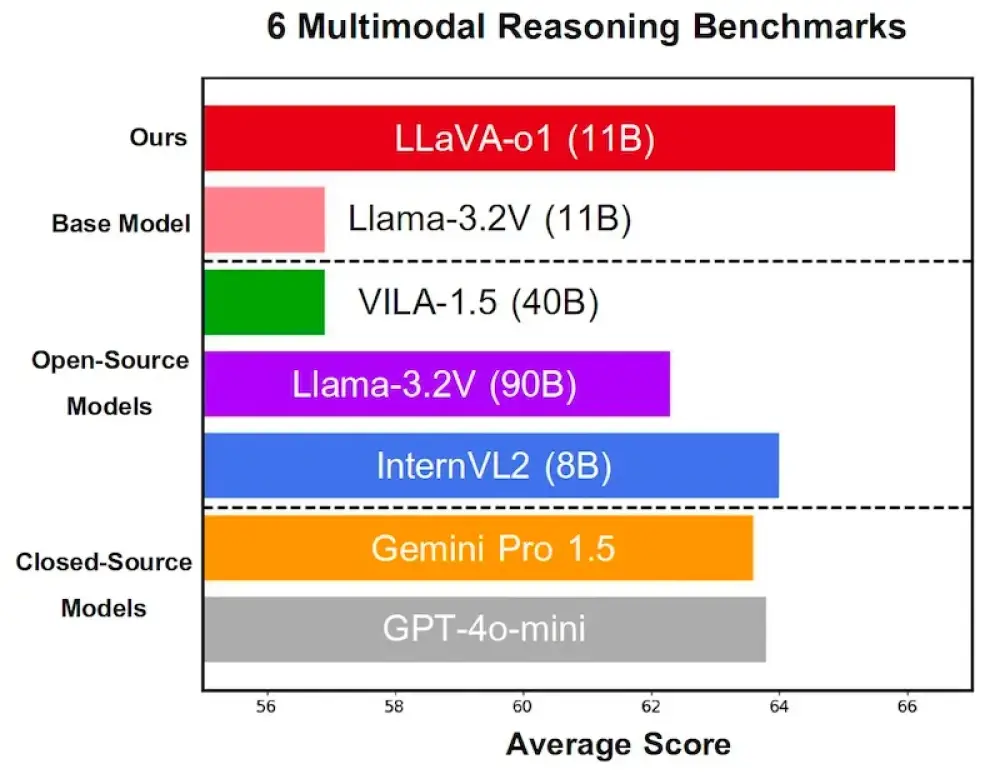
- Kết quả đánh giá:
+ Cải thiện 6,9% điểm benchmark so với mô hình Llama cơ bản
+ Vượt trội hơn các mô hình nguồn mở khác có cùng kích thước hoặc lớn hơn
+ Hiệu suất cao hơn một số mô hình đóng như GPT-4-o-mini và Gemini 1.5 Pro
- Đóng góp quan trọng:
+ Thiết lập tiêu chuẩn mới cho suy luận đa phương thức trong VLM
+ Mở đường cho nghiên cứu về suy luận có cấu trúc
+ Tiềm năng mở rộng với bộ xác minh bên ngoài và học tăng cường
📌 LLaVA-o1 đạt bước tiến vượt bậc với khả năng suy luận 4 giai đoạn và cải thiện 6,9% hiệu suất so với Llama cơ bản. Mô hình nguồn mở này thậm chí vượt qua các đối thủ lớn như GPT-4-o-mini và Gemini 1.5 Pro, mở ra hướng phát triển mới cho công nghệ VLM.
https://venturebeat.com/ai/chinese-researchers-unveil-llava-o1-to-challenge-openais-o1-model/



Thảo luận
Follow Us
Tin phổ biến
