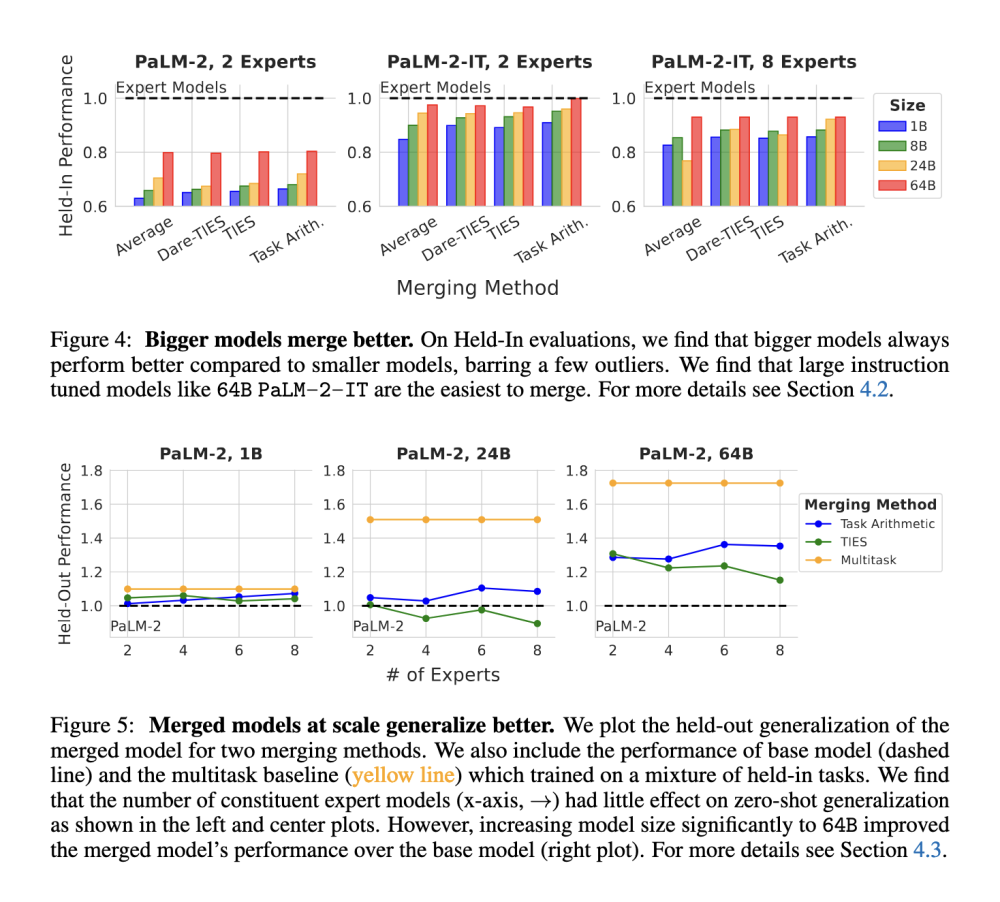
Hợp nhất 8 mô hình AI khổng lồ thành siêu trí tuệ 64 tỷ tham số
• Một nhóm nghiên cứu từ Đại học North Carolina, Google và Virginia Tech đã thực hiện nghiên cứu toàn diện về kỹ thuật hợp nhất mô hình quy mô lớn.
• Họ đánh giá việc hợp nhất các mô hình từ 1 tỷ đến 64 tỷ tham số, sử dụng tối đa 8 mô hình chuyên gia trong nhiều cấu hình khác nhau.
• Bốn phương pháp hợp nhất được đánh giá: lấy trung bình, số học nhiệm vụ, Dare-TIES và TIES-Merging.
• Hai mô hình cơ sở được sử dụng: PaLM-2 và PaLM-2-IT (phiên bản được huấn luyện theo hướng dẫn của PaLM-2).
• Mục tiêu là xem xét ảnh hưởng của chất lượng mô hình cơ sở, kích thước mô hình và số lượng chuyên gia đến hiệu quả tổng thể của mô hình được hợp nhất.
• Phương pháp bao gồm sử dụng các mô hình chuyên gia được tinh chỉnh đầy đủ cho các nhiệm vụ cụ thể, sau đó hợp nhất để đánh giá hiệu suất trên các nhiệm vụ đã biết và chưa biết.
• Kết quả cho thấy các mô hình lớn hơn (64 tỷ tham số) dễ hợp nhất hơn các mô hình nhỏ hơn.
• Việc hợp nhất cải thiện đáng kể khả năng khái quát hóa của các mô hình, đặc biệt khi sử dụng mô hình được huấn luyện theo hướng dẫn như PaLM-2-IT.
• Khi hợp nhất 8 mô hình chuyên gia lớn, các mô hình được hợp nhất vượt trội hơn các mô hình được đào tạo đa nhiệm vụ, đạt hiệu suất cao hơn trên các nhiệm vụ chưa biết.
• Hợp nhất các mô hình từ PaLM-2-IT dẫn đến khả năng khái quát hóa không cần mẫu tốt hơn so với PaLM-2 được đào tạo trước.
• Khoảng cách hiệu suất giữa các phương pháp hợp nhất khác nhau thu hẹp khi kích thước mô hình tăng lên.
• Hợp nhất nhiều mô hình chuyên gia hơn (lên đến 8) dẫn đến khả năng khái quát hóa tốt hơn mà không mất hiệu suất đáng kể.
• Các số liệu hiệu suất cho thấy các mô hình lớn hơn và được huấn luyện theo hướng dẫn có lợi thế rõ ràng.
• Hợp nhất 8 mô hình chuyên gia từ mô hình PaLM-2-IT 64 tỷ tham số đạt kết quả vượt trội so với đường cơ sở đào tạo đa nhiệm vụ.
• Các mô hình được hợp nhất thể hiện khả năng thích ứng tốt hơn với các nhiệm vụ mới so với các chuyên gia được tinh chỉnh riêng lẻ.
📌 Nghiên cứu cho thấy hợp nhất mô hình quy mô lớn là hướng đi đầy hứa hẹn để tạo ra các mô hình ngôn ngữ có khả năng khái quát hóa cao. Mô hình được huấn luyện theo hướng dẫn như PaLM-2-IT 64 tỷ tham số cho kết quả tốt nhất khi hợp nhất 8 chuyên gia, vượt trội so với đào tạo đa nhiệm vụ truyền thống.
https://www.marktechpost.com/2024/10/13/this-ai-paper-introduces-a-comprehensive-study-on-large-scale-model-merging-techniques/



Thảo luận
Follow Us
Tin phổ biến
