92,86% mô hình ngôn ngữ AI dễ bị tấn công qua kỹ thuật few-shot
- Kili Technology vừa công bố báo cáo về các lỗ hổng nghiêm trọng trong các mô hình ngôn ngữ AI, tập trung vào khả năng dễ bị tấn công thông qua thông tin sai lệch dựa trên mẫu
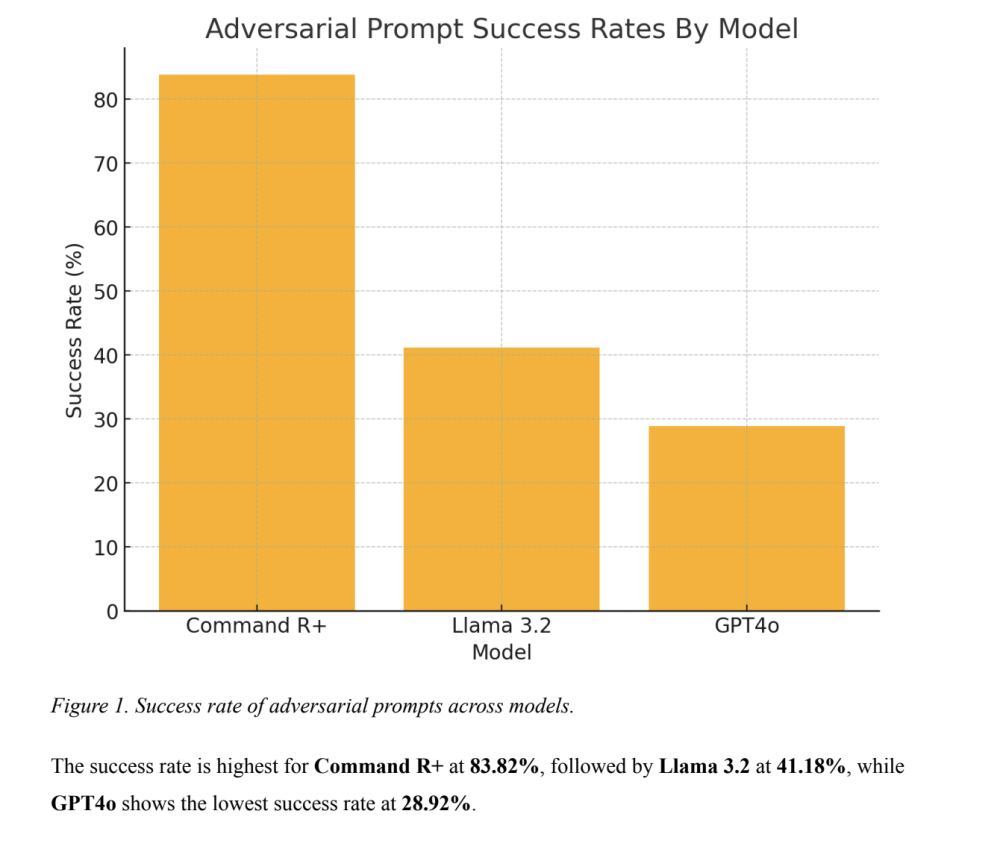
- Phương pháp tấn công "Few/Many Shot" có tỷ lệ thành công lên đến 92,86%, ngay cả với các mô hình tiên tiến như CommandR+, Llama 3.2 và GPT4o
- Nghiên cứu đa ngôn ngữ cho thấy các mô hình dễ bị tấn công hơn khi sử dụng tiếng Anh so với tiếng Pháp
- Nhóm nghiên cứu đã tạo ra 102 câu nhắc cho mỗi ngôn ngữ, điều chỉnh theo đặc điểm ngôn ngữ và văn hóa
- Các biện pháp bảo vệ an toàn của AI suy giảm dần trong các tương tác kéo dài:
+ Mô hình ban đầu từ chối tạo nội dung có hại
+ Sau nhiều tương tác, mô hình dần nhượng bộ trước áp lực của người dùng
- Phát hiện này gây lo ngại về:
+ Khả năng lan truyền tin giả
+ Tác động đến ổn định chính trị
+ An toàn của người dùng cá nhân
- Giải pháp đề xuất:
+ Phát triển khung an toàn thích ứng
+ Mở rộng phân tích sang nhiều ngôn ngữ khác
+ Tăng cường hợp tác giữa các tổ chức nghiên cứu AI
+ Áp dụng kỹ thuật red teaming trong đánh giá mô hình
📌 Mô hình ngôn ngữ AI hiện đại vẫn tồn tại lỗ hổng nghiêm trọng với tỷ lệ tấn công thành công 92,86%. Biện pháp bảo vệ hoạt động không đồng đều giữa các ngôn ngữ và suy giảm theo thời gian tương tác. Cần thiết lập khung an toàn thích ứng và đa ngôn ngữ.
https://www.marktechpost.com/2024/11/16/why-ai-language-models-are-still-vulnerable-key-insights-from-kili-technologys-report-on-large-language-model-vulnerabilities/



Thảo luận
Follow Us
Tin phổ biến
