NVIDIA ra mắt Fugatto - Siêu mô hình AI 2,5 tỷ tham số có thể biến piano thành giọng hát người thật
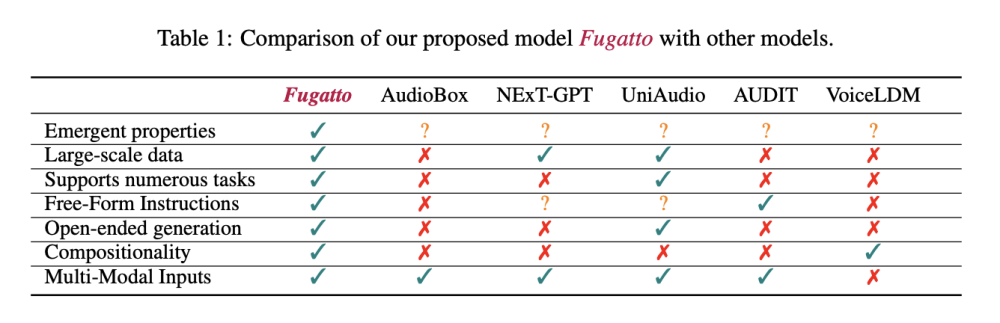
- NVIDIA vừa công bố Fugatto - mô hình AI có 2,5 tỷ tham số được thiết kế để tạo và điều chỉnh âm nhạc, giọng nói và âm thanh
- Mô hình cho phép kết hợp câu lệnh văn bản với khả năng tổng hợp âm thanh nâng cao, giúp biến đổi linh hoạt các đầu vào âm thanh như chuyển giai điệu piano thành giọng hát người hoặc tạo âm thanh kèn trumpet độc đáo
- Fugatto sử dụng phương pháp tạo dữ liệu đột phá vượt qua học có giám sát thông thường:
+ Kết hợp bộ dữ liệu thông thường với kỹ thuật tạo dữ liệu chuyên biệt
+ Tận dụng mô hình ngôn ngữ lớn để nâng cao khả năng tạo hướng dẫn
+ Hiểu sâu mối quan hệ giữa âm thanh và gợi ý văn bản
- Đột phá chính là kỹ thuật Composable Audio Representation Transformation (ComposableART):
+ Cho phép kết hợp, nội suy hoặc phủ định các hướng dẫn tạo âm thanh một cách mượt mà
+ Kiểm soát chính xác quá trình tổng hợp âm thanh
+ Tạo ra các hiện tượng âm thanh độc đáo
- Kiến trúc của Fugatto dựa trên mô hình Transformer được cải tiến với Adaptive Layer Normalization, giúp duy trì tính nhất quán trên nhiều đầu vào đa dạng
- Kết quả thử nghiệm cho thấy:
+ Hiệu suất vượt trội so với các mô hình chuyên biệt trong tổng hợp và biến đổi âm thanh
+ Khả năng tạo âm thanh mới như kèn saxophone với đặc tính bất thường
+ Tạo giọng nói tích hợp mượt mà với âm thanh nền
📌 Fugatto đánh dấu bước tiến quan trọng trong AI tạo sinh cho âm thanh với 2,5 tỷ tham số. Mô hình tích hợp công nghệ ComposableART độc đáo cho phép biến đổi linh hoạt từ piano sang giọng hát người thật, mở ra tiềm năng ứng dụng rộng rãi trong game, giải trí và giáo dục.
https://www.marktechpost.com/2024/11/25/nvidia-ai-unveils-fugatto-a-2-5-billion-parameter-audio-model-that-generates-music-voice-and-sound-from-text-and-audio-input/



Thảo luận
Follow Us
Tin phổ biến
