Meta-Rewarding: kỹ thuật giúp mô hình ngôn ngữ lớn tự đánh giá và cải thiện bản thân
• Các nhà nghiên cứu từ Meta FAIR, Đại học California, Berkeley và Đại học New York đã giới thiệu phương pháp Meta-Rewarding nhằm cải thiện khả năng tuân theo hướng dẫn của mô hình ngôn ngữ lớn (LLM).
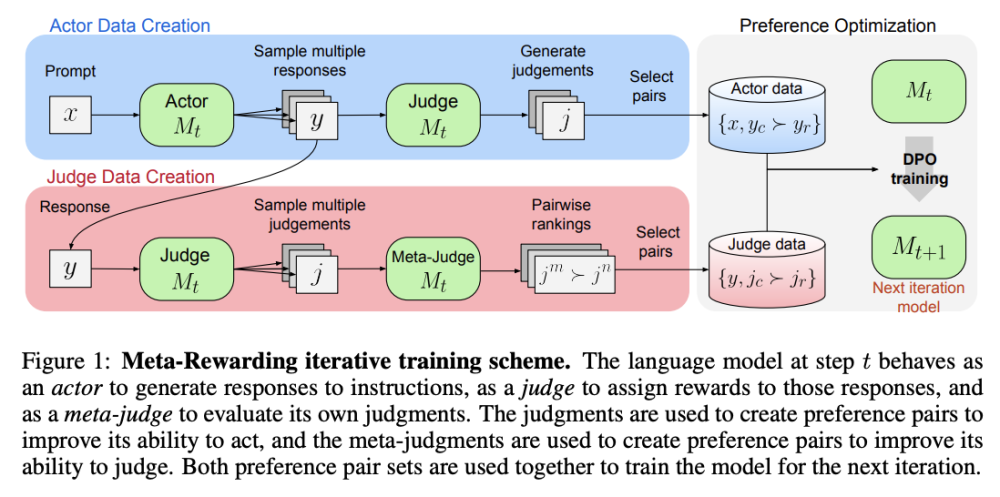
• Phương pháp này bổ sung vai trò thứ ba là meta-judge, bên cạnh hai vai trò actor và judge hiện có. Meta-judge đánh giá các phán đoán của mô hình thông qua cơ chế LLM-as-a-Meta-Judge.
• Meta-Rewarding tạo ra dữ liệu huấn luyện với các cặp phán đoán ưu tiên, ngoài các ưu tiên tiêu chuẩn giữa các phản hồi của actor. Điều này giúp cải thiện cả kỹ năng hành động và đánh giá của mô hình.
• Phương pháp được phát triển dựa trên mô hình Llama-3-8B-Instruct đã được tinh chỉnh theo hướng dẫn. Các nhà nghiên cứu thực hiện tinh chỉnh có giám sát (SFT) trên bộ dữ liệu Evaluation Fine-Tuning (EFT).
• Quá trình lặp lại Meta-Rewarding sử dụng 20.000 câu nhắc được tạo bởi Llama-2-70B-Chat. Mỗi lần lặp lấy mẫu 5.000 câu nhắc từ tập này, thực hiện 4 lần lặp.
• Kết quả đánh giá cho thấy tỷ lệ chiến thắng có kiểm soát độ dài tăng từ 22,9% lên 39,4% trên AlpacaEval, vượt trội hơn cả GPT-4-0314.
• Meta-Rewarding cũng vượt trội hơn phương pháp Self-Rewarding tiêu chuẩn nâng cao, với tỷ lệ chiến thắng 35,5%.
• Trên benchmark Arena-Hard, sau 4 lần lặp, Meta-Rewarding đạt được mức tăng 8,5% so với điểm 20,6% của mô hình gốc.
• Phương pháp này cũng bao gồm một kỹ thuật kiểm soát độ dài mới để giải quyết vấn đề bùng nổ độ dài trong quá trình huấn luyện phản hồi AI.
• Khả năng đánh giá của mô hình phù hợp hơn với đánh giá của con người và các mô hình AI tiên tiến như GPT-4.
• Một hạn chế được đề cập là hệ thống đánh giá 5 điểm đôi khi dẫn đến kết quả hòa do sự khác biệt tối thiểu về chất lượng phản hồi.
📌 Meta-Rewarding là kỹ thuật mới giúp LLM tự cải thiện khả năng tuân theo hướng dẫn, vượt trội hơn các phương pháp truyền thống. Kết quả trên AlpacaEval tăng từ 22,9% lên 39,4%, vượt qua cả GPT-4. Phương pháp này hứa hẹn giải quyết thách thức "Super Alignment" trong tương lai.
https://www.marktechpost.com/2024/08/07/meta-rewarding-llms-a-self-improving-alignment-technique-where-the-llm-judges-its-own-judgements-and-uses-the-feedback-to-improve-its-judgment-skills/



Thảo luận
Follow Us
Tin phổ biến
