MedFuzz: Phương pháp AI mới đánh giá độ mạnh mẽ của các mô hình hỏi đáp y tế trước nhiễu loạn
• Các nhà nghiên cứu từ Microsoft Research, MIT, Đại học Johns Hopkins và Helivan Research đã giới thiệu MedFuzz - một phương pháp kiểm tra đối kháng mới để đánh giá độ mạnh mẽ của các mô hình ngôn ngữ lớn (LLM) trong lĩnh vực hỏi đáp y tế.
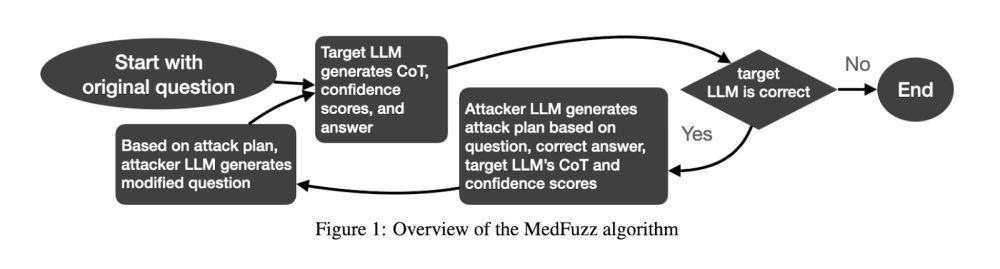
• MedFuzz được thiết kế để khám phá khả năng của LLM bằng cách thay đổi các câu hỏi từ các bộ đánh giá y tế theo cách vi phạm các giả định cơ bản của các bài kiểm tra này.
• Phương pháp này dựa trên kỹ thuật fuzz phần mềm, nơi dữ liệu không mong đợi được đưa vào hệ thống để phát hiện lỗ hổng.
• MedFuzz bắt đầu bằng cách chọn một câu hỏi từ bộ đánh giá y tế như MedQA-USMLE, sau đó sửa đổi một số chi tiết của câu hỏi như đặc điểm bệnh nhân để thách thức khả năng diễn giải và phản hồi chính xác của LLM.
• Mục tiêu không phải là làm cho câu hỏi khó hơn mà là xem LLM có thể áp dụng lập luận y tế chính xác trong điều kiện thực tế phức tạp hơn bao gồm các chi tiết bệnh nhân phức tạp hay không.
• Kết quả thí nghiệm cho thấy ngay cả các mô hình có độ chính xác cao như GPT-4 và các phiên bản PaLM-2 được tinh chỉnh về y tế cũng có thể bị đánh lừa để đưa ra câu trả lời không chính xác.
• Độ chính xác của GPT-4 trên MedQA giảm từ 90,2% xuống 85,4% khi được kiểm tra với các thay đổi MedFuzz.
• GPT-3.5, ban đầu đạt 60,2% trên MedQA, thậm chí còn hoạt động kém hơn trong các điều kiện đối kháng này.
• Nghiên cứu cũng xem xét các lời giải thích do LLM đưa ra khi tạo câu trả lời. Trong nhiều trường hợp, các mô hình không nhận ra rằng lỗi của chúng là do các chi tiết bệnh nhân được sửa đổi thông qua MedFuzz.
• Kết quả nghiên cứu nhấn mạnh nhu cầu cần có các khung đánh giá tốt hơn vượt ra ngoài các bộ đánh giá tĩnh và kiểm tra các mô hình trong các tình huống thực tế động.
• MedFuzz giúp thu hẹp khoảng cách giữa hiệu suất trên bộ đánh giá và khả năng áp dụng trong thế giới thực, cung cấp cách kiểm tra các mô hình đối với các kịch bản phức tạp hơn.
📌 MedFuzz là phương pháp mới đánh giá độ mạnh mẽ của LLM trong hỏi đáp y tế. Kết quả cho thấy ngay cả GPT-4 cũng giảm độ chính xác từ 90,2% xuống 85,4% khi bị nhiễu loạn. Nghiên cứu nhấn mạnh nhu cầu cải thiện phương pháp đánh giá LLM để đảm bảo sử dụng an toàn và hiệu quả trong y tế.
https://www.marktechpost.com/2024/09/13/microsoft-researchers-propose-medfuzz-a-new-ai-method-for-evaluating-the-robustness-of-medical-question-answering-llms-to-adversarial-perturbations/



Thảo luận
Follow Us
Tin phổ biến
