Llama3-V vượt trội so với GPT-3.5 và GPT-4 với mô hình nhỏ gọn và chi phí huấn luyện dưới 500 USD
- Llama3-V là một mô hình đa phương thức dựa trên Llama3, được huấn luyện với chi phí dưới 500 đô la.
- Mô hình tích hợp thông tin hình ảnh bằng cách nhúng ảnh đầu vào thành các embedding patch sử dụng mô hình SigLIP.
- Các embedding này được căn chỉnh với token văn bản thông qua khối projection sử dụng các khối self-attention, đặt embedding hình ảnh và văn bản trên cùng một mặt phẳng.
- Token hình ảnh được thêm vào trước token văn bản và biểu diễn kết hợp được xử lý qua Llama3.
- SigLIP sử dụng sigmoid loss cho từng cặp ảnh-văn bản, chia ảnh thành các patch không chồng lấp, chiếu chúng vào không gian embedding có chiều thấp hơn và áp dụng self-attention.
- Để tối ưu hóa tài nguyên tính toán, Llama3-V sử dụng cơ chế lưu trữ đệm để tính toán trước các embedding ảnh SigLIP và tận dụng các tối ưu hóa MPS/MLX.
- Quá trình tiền huấn luyện sử dụng 600.000 cặp ảnh-văn bản, chỉ cập nhật ma trận projection. Tinh chỉnh có giám sát sử dụng 1 triệu mẫu, tập trung vào ma trận vision và projection.
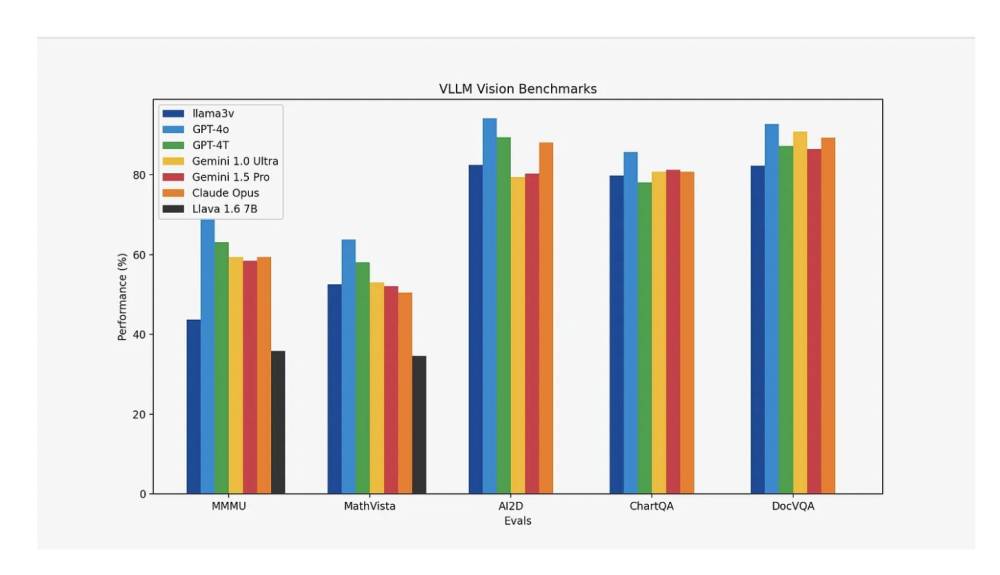
- Llama3-V đạt mức tăng hiệu suất 10-20% so với Llava, mô hình hàng đầu về hiểu biết đa phương thức, và có hiệu suất tương đương với các mô hình nguồn đóng lớn hơn nhiều trên hầu hết các chỉ số, ngoại trừ MMMU.
📌 Llama3-V thể hiện những tiến bộ đáng kể trong AI đa phương thức, vượt trội hơn Llava 10-20% và sánh ngang với các mô hình nguồn đóng lớn hơn trên hầu hết các chỉ số. Với việc tích hợp SigLIP để nhúng ảnh hiệu quả và các tối ưu hóa tính toán, Llama3-V tối đa hóa việc sử dụng GPU và giảm chi phí huấn luyện, thiết lập nó như một mô hình SOTA cạnh tranh và hiệu quả cho hiểu biết đa phương thức.
https://www.marktechpost.com/2024/05/31/llama3-v-a-sota-open-source-vlm-model-comparable-performance-to-gpt4-v-gemini-ultra-claude-opus-with-a-100x-smaller-model/



Thảo luận
Follow Us
Tin phổ biến
