Linkedin ra mắt Liger Kernel: công cụ đột phá tăng 20% hiệu suất đào tạo LLM, giảm 60% bộ nhớ
• LinkedIn vừa công bố Liger (LinkedIn GPU Efficient Runtime) Kernel - bộ Triton kernel hiệu quả cao được thiết kế riêng cho việc đào tạo mô hình ngôn ngữ lớn (LLM).
• Liger Kernel tăng thông lượng đào tạo đa GPU lên hơn 20% và giảm sử dụng bộ nhớ tới 60% thông qua kỹ thuật hợp nhất kernel, thay thế tại chỗ và phân đoạn.
• Công cụ này tương thích với Flash Attention, PyTorch FSDP và Microsoft DeepSpeed, chỉ yêu cầu Torch và Triton làm phụ thuộc.
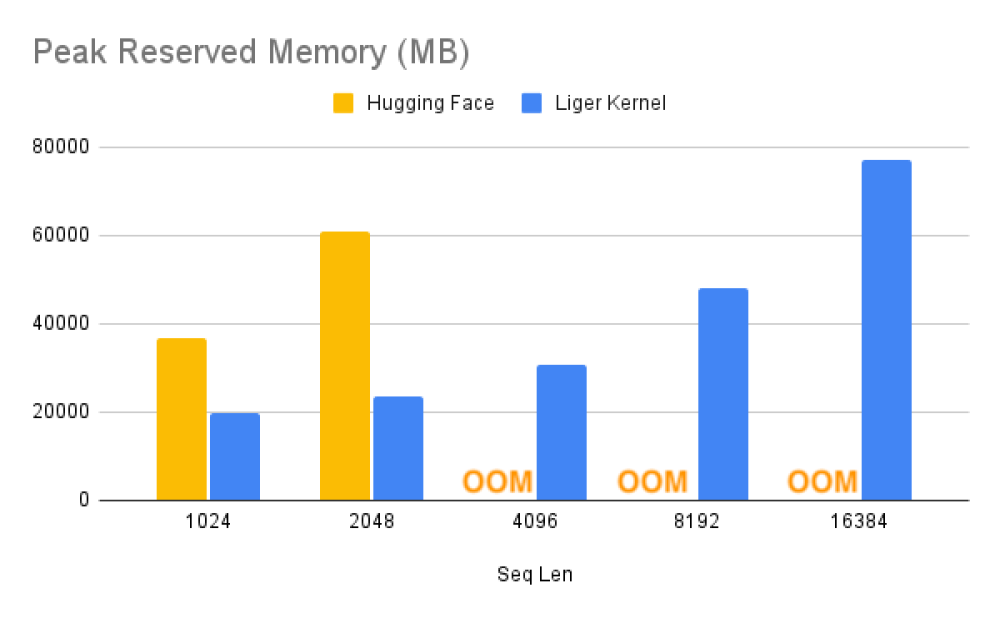
• Liger Kernel cho phép xử lý độ dài ngữ cảnh lớn hơn, kích thước batch lớn hơn và từ vựng khổng lồ mà không ảnh hưởng hiệu suất. Nó có thể mở rộng lên đến 16K trong khi các mô hình Hugging Face truyền thống gặp lỗi hết bộ nhớ ở 4K.
• Khi đào tạo mô hình LLaMA 3-8B, Liger Kernel có thể tăng tốc độ đào tạo lên 20% và giảm 40% sử dụng bộ nhớ.
• Trong giai đoạn đào tạo lại của LLM đa đầu như Medusa, Liger Kernel giảm 80% sử dụng bộ nhớ và tăng 40% thông lượng.
• Liger Kernel tích hợp các phép toán dựa trên Triton như RMSNorm, RoPE, SwiGLU và FusedLinearCrossEntropy để nâng cao hiệu suất đào tạo LLM.
• RMSNorm trong Liger Kernel đạt tốc độ tăng gấp 3 lần và giảm bộ nhớ đỉnh. RoPE và SwiGLU được triển khai với kỹ thuật thay thế tại chỗ giúp giảm đáng kể sử dụng bộ nhớ và tăng tốc độ tính toán.
• Hàm mất mát CrossEntropy được tối ưu hóa để giảm bộ nhớ đỉnh hơn 4 lần và tăng gấp đôi tốc độ thực thi.
• Người dùng có thể dễ dàng tích hợp Liger Kernel vào quy trình làm việc hiện có bằng một dòng mã để vá các mô hình Hugging Face.
• Liger Kernel có thể cài đặt qua pip với cả phiên bản ổn định và nightly.
• LinkedIn cam kết tiếp tục cải tiến Liger Kernel và hoan nghênh sự đóng góp từ cộng đồng để thu thập các kernel tốt nhất cho đào tạo LLM.
📌 Liger Kernel của LinkedIn là bước đột phá trong đào tạo LLM, tăng hiệu suất 20% và giảm 60% bộ nhớ. Công cụ này hứa hẹn thúc đẩy phát triển các mô hình AI tiên tiến hơn, mở ra nhiều khả năng mới trong lĩnh vực trí tuệ nhân tạo.
https://www.marktechpost.com/2024/08/25/linkedin-released-liger-linkedin-gpu-efficient-runtime-kernel-a-revolutionary-tool-that-boosts-llm-training-efficiency-by-over-20-while-cutting-memory-usage-by-60/



Thảo luận
Follow Us
Tin phổ biến
