Idefics3-8B-Llama3: Cải thiện đáng kể hiệu suất trong các tác vụ hỏi đáp tài liệu và suy luận hình ảnh
• HuggingFace vừa phát hành Idefics3-8B-Llama3, một mô hình đa phương thức tiên tiến được thiết kế để cải thiện khả năng hỏi đáp tài liệu.
• Mô hình này kết hợp SigLip vision backbone với Llama 3.1 text backbone, hỗ trợ đầu vào văn bản và hình ảnh với tối đa 10.000 token ngữ cảnh.
• Idefics3-8B-Llama3 được cấp phép theo Apache 2.0, đại diện cho một bước tiến đáng kể so với các phiên bản trước đó.
• Mô hình có 8,5 tỷ tham số, cho phép xử lý các đầu vào đa dạng, bao gồm cả tài liệu phức tạp có cả văn bản và hình ảnh.
• Cải tiến bao gồm xử lý tốt hơn các token hình ảnh bằng cách mã hóa hình ảnh thành 169 token hình ảnh và tích hợp bộ dữ liệu tinh chỉnh mở rộng như Docmatix.
• Mục tiêu của phương pháp này là tinh chỉnh khả năng hiểu tài liệu và cải thiện hiệu suất tổng thể trong các tác vụ đa phương thức.
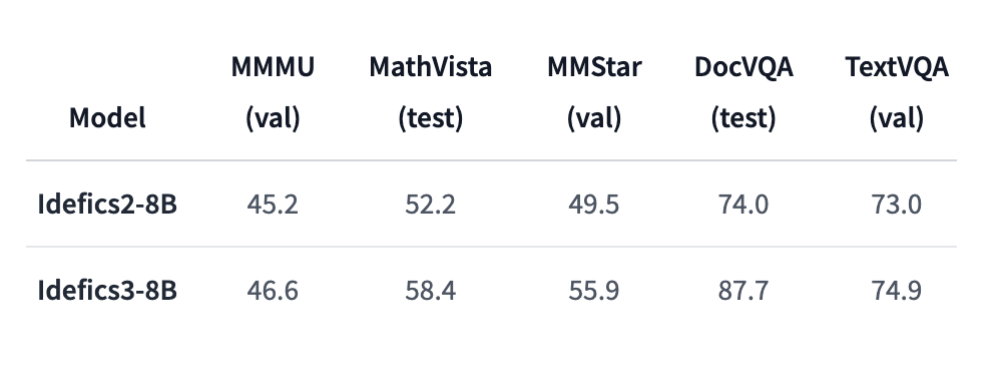
• Đánh giá hiệu suất cho thấy Idefics3-8B-Llama3 đạt độ chính xác 87,7% trong DocVQA và 55,9% trong MMStar, so với 49,5% trong DocVQA và 45,2% trong MMMU của Idefics2.
• Kết quả này cho thấy những cải tiến đáng kể trong việc xử lý các truy vấn dựa trên tài liệu và suy luận hình ảnh.
• Khả năng quản lý tối đa 10.000 token ngữ cảnh và tích hợp với các công nghệ tiên tiến góp phần vào những cải thiện hiệu suất này.
• Idefics3-8B-Llama3 đại diện cho một bước tiến lớn trong xử lý tài liệu đa phương thức, giải quyết các hạn chế trước đây và mang lại độ chính xác và hiệu quả cao hơn.
• Mô hình này cung cấp một công cụ có giá trị cho các ứng dụng yêu cầu tích hợp dữ liệu văn bản và hình ảnh phức tạp.
• Những cải tiến trong hỏi đáp tài liệu và suy luận hình ảnh nhấn mạnh tiềm năng của nó cho nhiều trường hợp sử dụng khác nhau.
📌 Idefics3-8B-Llama3, mô hình đa phương thức mới từ HuggingFace, đạt độ chính xác 87,7% trong DocVQA và 55,9% trong MMStar. Với 8,5 tỷ tham số và khả năng xử lý 10.000 token ngữ cảnh, mô hình hứa hẹn cải thiện đáng kể hiệu suất trong hỏi đáp tài liệu và suy luận hình ảnh.
https://www.marktechpost.com/2024/08/09/idefics3-8b-llama3-released-an-open-multimodal-model-that-accepts-arbitrary-sequences-of-image-and-text-inputs-and-produces-text-outputs/



Thảo luận
Follow Us
Tin phổ biến
