Hymba 1.5B của NVIDIA: Mô hình ngôn ngữ nhỏ hybrid đánh bại Llama 3.2 và SmolLM v2
- NVIDIA giới thiệu mô hình Hymba 1.5B, một mô hình ngôn ngữ nhỏ hybrid với 1,5 tỷ tham số.
- Hymba kết hợp giữa Mamba và các attention heads, giúp tăng cường hiệu suất và hiệu quả cho các mô hình NLP nhỏ.
- Mô hình này được huấn luyện trên 1,5 triệu tệp dữ liệu (tokens), cho phép xử lý nhanh và tiết kiệm tài nguyên.
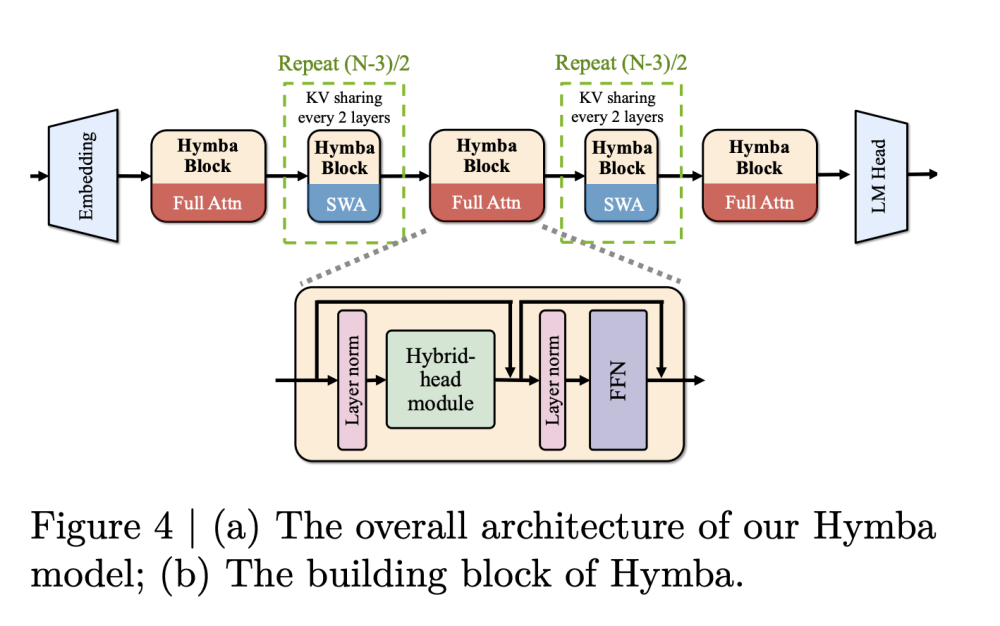
- Kiến trúc hybrid-head parallel cho phép các attention heads và SSM xử lý dữ liệu đầu vào song song, kết hợp ưu điểm của cả hai phương pháp.
- Hymba sử dụng các meta token có thể học được, được chèn vào từng đầu vào để lưu trữ thông tin quan trọng, giảm tải cho các cơ chế chú ý.
- Mô hình tối ưu hóa với việc chia sẻ khóa-giá trị (KV) giữa các lớp và cửa sổ trượt một phần, giúp duy trì kích thước bộ nhớ gọn gàng.
- Mô hình có 16 trạng thái SSM và 3 lớp chú ý đầy đủ, phần còn lại sử dụng chú ý cửa sổ trượt để cân bằng giữa hiệu suất và độ phân giải bộ nhớ.
- Hymba-1.5B-Base vượt qua tất cả các mô hình công khai dưới 2B, đạt độ chính xác trung bình cao hơn Llama-3.2-3B 1,32% với kích thước bộ nhớ cache giảm 11,67 lần.
- Tốc độ xử lý khoảng 664 token mỗi giây, cao hơn so với SmolLM2 và Llama-3.2-3B, cho thấy tính khả thi trong các tình huống thực tế.
- Hymba thể hiện khả năng vượt trội trong nhiều tác vụ, đặc biệt là các nhiệm vụ yêu cầu nhớ nhiều thông tin.
📌 NVIDIA đã phát triển mô hình Hymba 1.5B với 1,5 tỷ tham số, vượt trội hơn Llama 3.2 với độ chính xác cao hơn 1,32% và tốc độ xử lý 664 token mỗi giây, cho thấy khả năng hoạt động hiệu quả trên thiết bị hạn chế.
https://www.marktechpost.com/2024/11/22/nvidia-introduces-hymba-1-5b-a-hybrid-small-language-model-outperforming-llama-3-2-and-smollm-v2/



Thảo luận
Follow Us
Tin phổ biến
