Hướng dẫn toàn diện về cách sử dụng các mô hình nhúng văn bản của OpenAI
• Vector nhúng là biểu diễn số của dữ liệu phi cấu trúc như văn bản, video, âm thanh, hình ảnh. Chúng nắm bắt ý nghĩa ngữ nghĩa và mối quan hệ trong dữ liệu.
• Mô hình nhúng là thuật toán chuyên biệt chuyển đổi dữ liệu phi cấu trúc thành vector nhúng. Nó học các mẫu và mối quan hệ trong dữ liệu và biểu diễn chúng trong không gian đa chiều.
• OpenAI cung cấp một số mô hình nhúng văn bản phù hợp cho các tác vụ như tìm kiếm ngữ nghĩa, phân cụm, hệ thống đề xuất, phát hiện bất thường, đo lường đa dạng và phân loại.
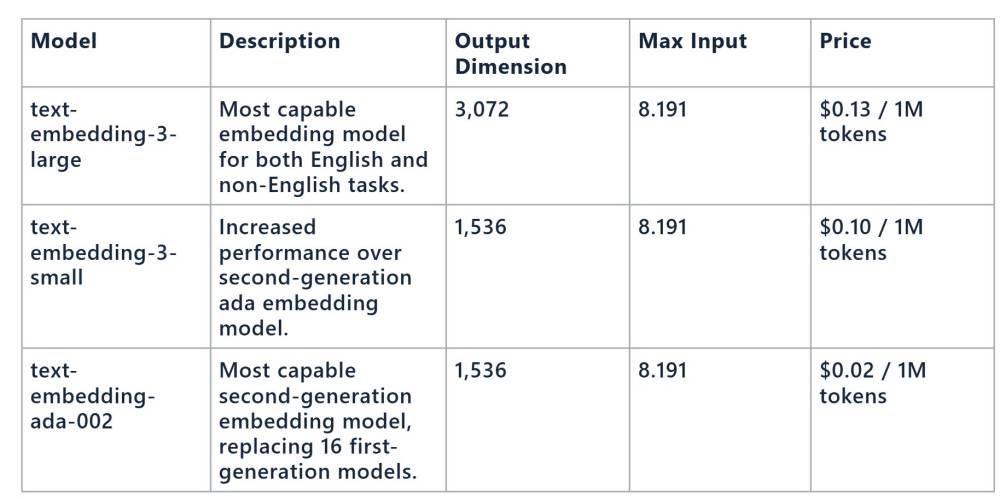
• 3 mô hình nhúng văn bản chính của OpenAI là:
- text-embedding-ada-002: Mô hình thế hệ thứ hai có khả năng nhất, thay thế 16 mô hình thế hệ đầu tiên.
- text-embedding-3-small: Hiệu suất cao hơn mô hình ada thế hệ thứ hai.
- text-embedding-3-large: Mô hình nhúng có khả năng nhất cho cả tiếng Anh và các ngôn ngữ khác.
• Khi chọn mô hình, cần cân nhắc giữa độ chính xác, tài nguyên tính toán và tốc độ phản hồi truy vấn.
• Để tạo vector nhúng với các mô hình OpenAI, cần sử dụng thư viện PyMilvus và OpenAI Python. Các bước chính bao gồm:
1. Đăng ký tài khoản Zilliz Cloud miễn phí
2. Thiết lập cụm serverless và lấy endpoint công khai và API key
3. Tạo bộ sưu tập vector và chèn vector nhúng
4. Chạy tìm kiếm ngữ nghĩa trên các nhúng đã lưu trữ
• Bài viết cung cấp các đoạn mã Python mẫu để tạo vector nhúng với cả 3 mô hình và lưu trữ chúng trong Zilliz Cloud để tìm kiếm ngữ nghĩa.
• Ngoài các mô hình của OpenAI, còn có nhiều mô hình AI khác tương thích với Milvus có thể sử dụng tùy theo nhu cầu cụ thể.
📌 OpenAI cung cấp 3 mô hình nhúng văn bản chính: ada-002, 3-small và 3-large với các đặc điểm khác nhau. Việc chọn mô hình phụ thuộc vào cân bằng giữa độ chính xác, tài nguyên và tốc độ. PyMilvus và Zilliz Cloud giúp tạo và lưu trữ vector nhúng dễ dàng cho tìm kiếm ngữ nghĩa.
https://thenewstack.io/beginners-guide-to-openai-text-embedding-models/



Thảo luận
Follow Us
Tin phổ biến
