Deepseek V3: Mô hình ngôn ngữ nguồn mở mạnh nhất Trung Quốc ra mắt với tốc độ và hiệu năng vượt trội
- Deepseek V3 là mô hình ngôn ngữ nguồn mở mạnh mẽ nhất do công ty AI Trung Quốc phát triển.
- Mô hình này sử dụng kiến trúc Mixture-of-Experts (MoE) với 671 tỷ tham số, trong đó 37 tỷ tham số được kích hoạt cho mỗi token.
- So với phiên bản V2, V3 đã tăng gần gấp 3 lần số tham số, từ 236 tỷ lên 671 tỷ.
- V3 được huấn luyện với 14.8 triệu tỷ token, gấp gần 2 lần dữ liệu huấn luyện của V2.
- Thời gian huấn luyện tổng cộng là 2.788 triệu giờ GPU H800 với chi phí khoảng 5.576 triệu USD.
- Điều đáng chú ý là Deepseek chỉ sử dụng 2.000 GPU, rất ít so với 100.000 GPU mà các công ty lớn như Meta hay OpenAI thường sử dụng.
- Tốc độ xử lý của V3 đạt 60 token mỗi giây, nhanh gấp 3 lần so với phiên bản trước.
- Mô hình này đạt điểm cao nhất trong 3 trong 6 bài kiểm tra lớn về LLM, đặc biệt là bài kiểm tra MATH 500 với tỷ lệ chính xác 90.2%.
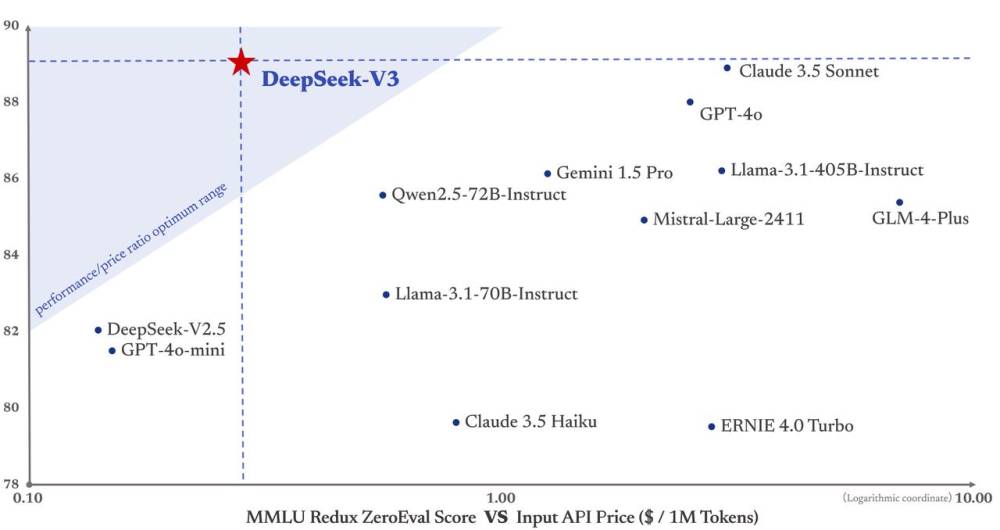
- Deepseek V3 cạnh tranh sòng phẳng với các mô hình độc quyền như GPT-4o và Claude-3.5-Sonnet.
- Mức giá API sẽ giữ nguyên cho đến ngày 8 tháng 2, sau đó sẽ là 0.27 USD cho mỗi triệu token đầu vào và 1.10 USD cho mỗi triệu token đầu ra.
- Deepseek cấp phép theo Giấy phép Deepseek 1.0, cho phép người dùng tái sản xuất, sửa đổi và phân phối mô hình, trừ các ứng dụng quân sự và dịch vụ pháp lý tự động hoàn toàn.
- Công ty dự định sẽ cải thiện kiến trúc mô hình và phá vỡ giới hạn của Transformer, đồng thời hỗ trợ chiều dài ngữ cảnh không giới hạn.
📌 Deepseek V3 ra mắt với 671 tỷ tham số, tốc độ 60 token/giây, và đạt tỷ lệ chính xác 90.2% trong bài kiểm tra MATH 500. Với chi phí hợp lý, mô hình này đang cạnh tranh với các sản phẩm hàng đầu như GPT-4o và Claude-3.5.
https://the-decoder.com/deepseek-v3-emerges-as-chinas-most-powerful-open-source-language-model-to-date/



Thảo luận
Follow Us
Tin phổ biến
