DeepSeek AI giới thiệu NSA - cơ chế sparse attention mới tối ưu cho phần cứng tăng tốc xử lý AI lên tới 9 lần
-
DeepSeek AI vừa giới thiệu cơ chế NSA (Native Sparse Attention) - một giải pháp mới để xử lý hiệu quả các chuỗi văn bản dài trong mô hình ngôn ngữ
-
NSA giải quyết thách thức về độ phức tạp của attention truyền thống khi xử lý chuỗi dài bằng cách:
-
Nén nhóm token thành các biểu diễn tóm tắt
-
Chọn lọc các token quan trọng nhất
-
Sử dụng cửa sổ trượt để duy trì ngữ cảnh cục bộ
-
-
Kiến trúc NSA được tối ưu cho phần cứng GPU hiện đại:
-
Tải queries theo nhóm vào SRAM
-
Giảm thiểu truy cập bộ nhớ dư thừa
-
Chia sẻ bộ nhớ hiệu quả
-
-
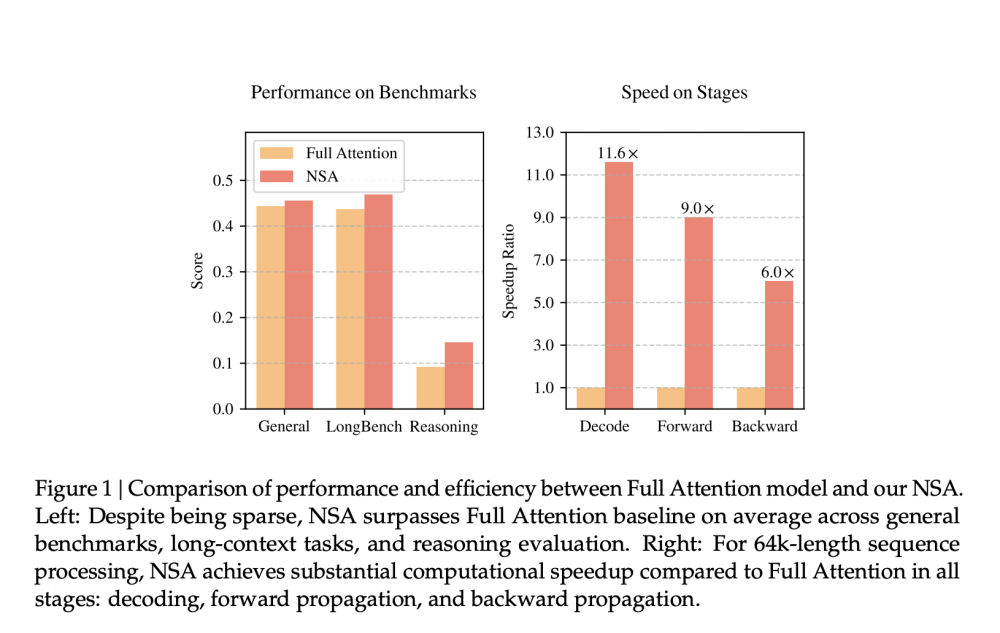
Kết quả thực nghiệm ấn tượng:
-
Tăng tốc tới 9 lần trong lan truyền xuôi
-
Tăng tốc 6 lần trong lan truyền ngược với chuỗi dài
-
Hiệu năng tương đương hoặc tốt hơn attention truyền thống trên các benchmark như MMLU, GSM8K, DROP
-
-
NSA hoạt động hiệu quả với chuỗi dài tới 64.000 token nhờ thiết kế phân cấp kết hợp:
-
Quét tổng quan toàn cục
-
Chọn lọc chi tiết cục bộ
-
Xử lý qua cửa sổ trượt
-
📌 Giải pháp NSA của DeepSeek AI đạt bước tiến quan trọng trong xử lý ngữ cảnh dài, tăng tốc tới 9 lần nhờ tối ưu phần cứng và thuật toán ba tầng: nén token, chọn lọc attention và cửa sổ trượt. Công nghệ này có thể xử lý hiệu quả chuỗi lên tới 64.000 token.
https://www.marktechpost.com/2025/02/18/deepseek-ai-introduces-nsa-a-hardware-aligned-and-natively-trainable-sparse-attention-mechanism-for-ultra-fast-long-context-training-and-inference/



Thảo luận
Follow Us
Tin phổ biến
