Các nhà nghiên cứu từ Apple tiết lộ DataComp: Bộ dữ liệu cặp văn bản-hình ảnh đột phá 12,8 tỷ để đo điểm chuẩn và phát triển mô hình học máy nâng cao
-
Các nhà nghiên cứu từ Apple và Đại học Washington giới thiệu DATACOMP, một bộ dữ liệu testbed đa phương tiện bao gồm 12.8 tỷ cặp dữ liệu ảnh và văn bản từ Common Crawl.
-
Công trình trước đây tập trung vào việc cải thiện hiệu suất mô hình thông qua việc làm sạch dữ liệu, loại bỏ ngoại lệ và chọn core set. DATACOMP giúp giải quyết thách thức từ tính chất độc quyền của các bộ dữ liệu đa phương tiện quy mô lớn, thúc đẩy nghiên cứu data-centric.
-
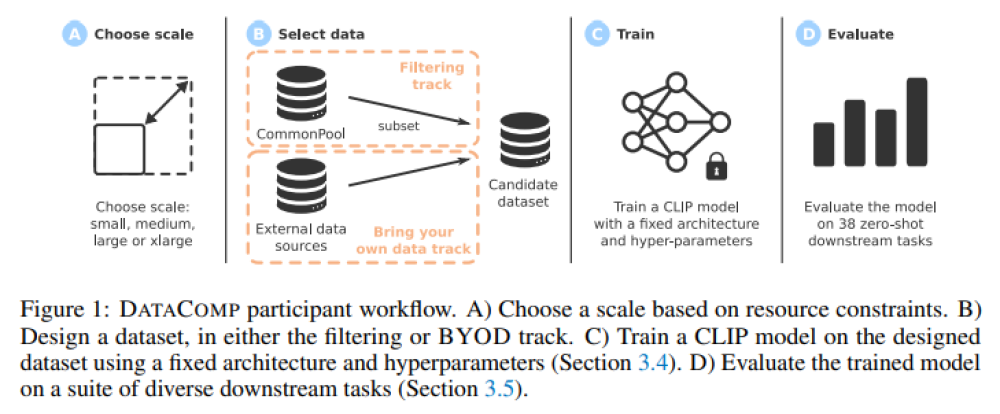
DATACOMP là một testbed cho thử nghiệm bộ dữ liệu đa phương tiện, cho phép thiết kế và đánh giá các kỹ thuật lọc mới, cải thiện thiết kế dữ liệu và hiệu suất mô hình đa phương tiện.
-
Bộ dữ liệu DATACOMP sử dụng mã huấn luyện CLIP chuẩn và thử nghiệm trên 38 tập dữ liệu phụ, cùng kiến trúc ViT được chọn vì xu hướng mở rộng CLIP thuận lợi hơn so với ResNets.
-
DATACOMP-1B đã cải thiện được 3.7 điểm phần trăm về độ chính xác zero-shot trên ImageNet so với CLIP ViT-L/14 của OpenAI (đạt 79.2%). Bộ dữ liệu và mã nguồn của DATACOMP được công bố để nghiên cứu và thử nghiệm rộng rãi.
📌 DATACOMP mở ra cơ hội mới cho nghiên cứu về bộ dữ liệu đa phương tiện, với 12.8 tỷ cặp ảnh-văn bản từ Common Crawl, cải thiện kỹ thuật lọc và đánh giá dữ liệu, và cung cấp hiểu biết sâu sắc hơn về thiết kế và hiệu suất mô hình đa phương tiện.



Thảo luận
Follow Us
Tin phổ biến
