AMD ra mắt mô hình ngôn ngữ AMD-135M với 135 triệu tham số, tối ưu hóa cho GPU MI250
• AMD vừa giới thiệu mô hình ngôn ngữ mới AMD-135M (hay AMD-Llama-135M), dựa trên kiến trúc LLaMA2 với 135 triệu tham số.
• Mô hình được tối ưu hóa cho GPU MI250 mới nhất của AMD, đánh dấu bước tiến quan trọng trong nỗ lực của AMD trong lĩnh vực AI.
• AMD-135M có cấu trúc gồm 12 lớp, 12 đầu chú ý, kích thước ẩn 768, sử dụng hàm kích hoạt Swiglu và chuẩn hóa lớp RMSNorm.
• Mô hình được huấn luyện trước trên hai bộ dữ liệu chính: SlimPajama (phiên bản đã loại bỏ trùng lặp của RedPajama) và Project Gutenberg.
• AMD-135M tích hợp với thư viện Hugging Face Transformers, giúp dễ dàng triển khai và sử dụng.
• Kích thước cửa sổ ngữ cảnh là 2048, cho phép xử lý hiệu quả các chuỗi đầu vào lớn hơn.
• Cấu hình huấn luyện sử dụng tốc độ học 6e-4 với lịch trình tốc độ học cosine, trải qua nhiều epoch.
• AMD-135M tương thích với giải mã suy đoán cho CodeLlama của AMD, mở rộng khả năng sử dụng cho các tác vụ tạo mã.
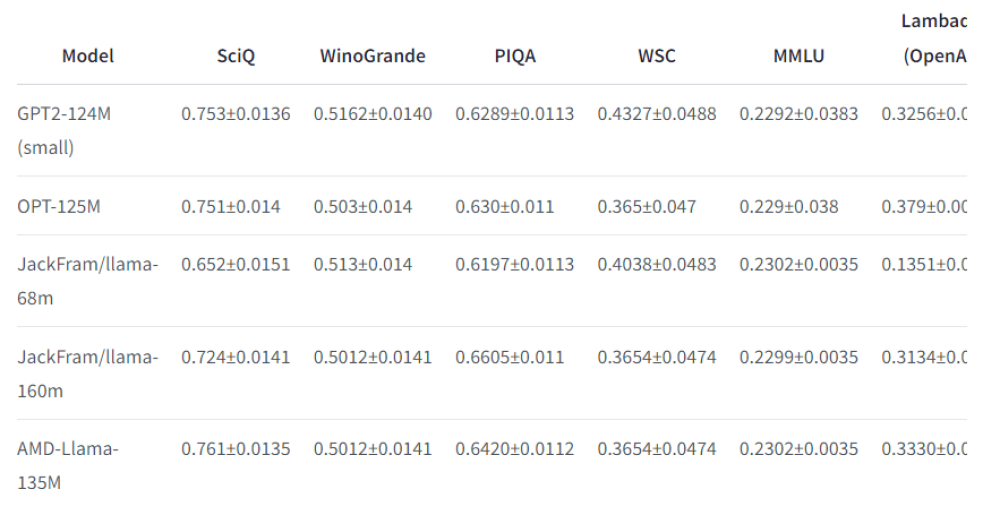
• Hiệu suất của mô hình được đánh giá bằng lm-evaluation-harness trên nhiều bài kiểm tra NLP như SciQ, WinoGrande và PIQA.
• Trên bộ dữ liệu Humaneval, AMD-135M đạt tỷ lệ vượt qua khoảng 32,31% khi sử dụng GPU MI250.
• Mô hình có thể được triển khai dễ dàng thông qua các module LlamaForCausalLM và AutoTokenizer của Hugging Face Transformers.
• AMD-135M được kỳ vọng sẽ là một đối thủ cạnh tranh mạnh mẽ trong lĩnh vực mô hình AI, phù hợp cho cả nghiên cứu và ứng dụng thương mại.
📌 AMD-135M là mô hình ngôn ngữ 135 triệu tham số dựa trên LLaMA2, tối ưu cho GPU MI250. Được huấn luyện trên SlimPajama và Project Gutenberg, mô hình đạt hiệu suất cao trên nhiều bài kiểm tra NLP, với tỷ lệ vượt qua 32,31% trên Humaneval, thể hiện tiềm năng lớn trong xử lý ngôn ngữ tự nhiên.
https://www.marktechpost.com/2024/09/28/amd-releases-amd-135m-amds-first-small-language-model-series-trained-from-scratch-on-amd-instinct-mi250-accelerators-utilizing-670b-tokens/



Thảo luận
Follow Us
Tin phổ biến
