Tin chính chủ OpenAI: o1 vượt trình độ tiến sĩ trong một số lĩnh vực
• OpenAI giới thiệu mô hình ngôn ngữ lớn mới có tên o1, được đào tạo bằng học tăng cường để thực hiện suy luận phức tạp.
• o1 có khả năng tạo ra chuỗi suy nghĩ dài trước khi đưa ra câu trả lời cho người dùng.
• Mô hình này đạt thứ hạng 89% trên các câu hỏi lập trình cạnh tranh (Codeforces), nằm trong top 500 học sinh tại Mỹ trong vòng loại cho Olympic Toán học Mỹ (AIME).
• o1 vượt qua độ chính xác của con người ở cấp độ tiến sĩ trên một bộ đánh giá về các vấn đề vật lý, sinh học và hóa học (GPQA).
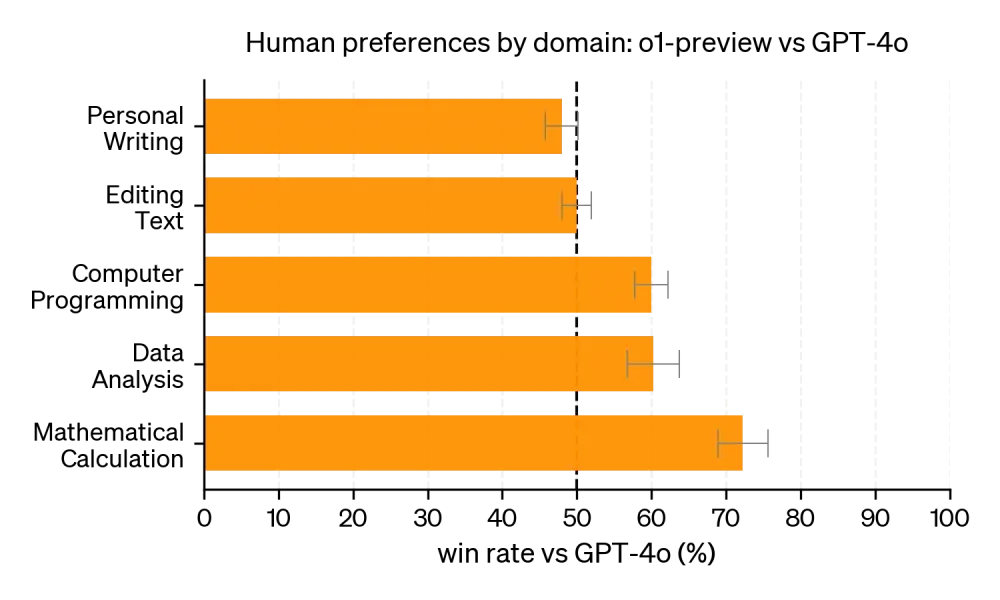
• OpenAI đang phát hành phiên bản sớm o1-preview để sử dụng ngay trong ChatGPT và cho các người dùng API đáng tin cậy.
• Thuật toán học tăng cường quy mô lớn dạy mô hình cách suy nghĩ hiệu quả sử dụng chuỗi suy nghĩ trong quá trình đào tạo hiệu quả về dữ liệu.
• Hiệu suất của o1 cải thiện nhất quán với nhiều học tăng cường hơn (thời gian tính toán khi đào tạo) và nhiều thời gian suy nghĩ hơn (thời gian tính toán khi kiểm tra).
• o1 vượt trội hơn đáng kể so với GPT-4o trong phần lớn các tác vụ đòi hỏi suy luận cao.
• Trên kỳ thi AIME 2024, GPT-4o chỉ giải được trung bình 12% (1,8/15) số bài toán. o1 đạt trung bình 74% (11,1/15) với một mẫu cho mỗi bài toán, 83% (12,5/15) với sự đồng thuận giữa 64 mẫu.
• Khi xếp hạng lại 1.000 mẫu bằng hàm chấm điểm đã học, o1 đạt 93% (13,9/15) trên AIME, đặt nó trong top 500 học sinh quốc gia và vượt qua ngưỡng cho Olympic Toán học Mỹ.
• Trên GPQA diamond, o1 vượt qua hiệu suất của các chuyên gia có bằng tiến sĩ, trở thành mô hình đầu tiên làm được điều này trên bộ đánh giá này.
• Với khả năng nhận thức hình ảnh được kích hoạt, o1 đạt 78,2% trên MMMU, là mô hình đầu tiên cạnh tranh với các chuyên gia.
• o1 vượt trội hơn GPT-4o trong 54/57 danh mục phụ của MMLU.
• Thông qua học tăng cường, o1 học cách tinh chỉnh chuỗi suy nghĩ và cải thiện các chiến lược nó sử dụng.
• Mô hình học cách nhận ra và sửa lỗi, chia nhỏ các bước phức tạp thành các bước đơn giản hơn, và thử cách tiếp cận khác khi cách hiện tại không hiệu quả.
📌 OpenAI giới thiệu mô hình o1 với khả năng suy luận vượt trội, đạt hiệu suất cao trên nhiều bài kiểm tra khó như AIME (83%) và GPQA. o1 cạnh tranh với chuyên gia trong một số lĩnh vực, mở ra tiềm năng mới cho AI trong giải quyết vấn đề phức tạp.
https://openai.com/index/learning-to-reason-with-llms/



Thảo luận
Follow Us
Tin phổ biến
