Nghiên cứu mới về thiết kế bộ dữ liệu Q&A: sử dụng kiến thức phổ biến trong fine-tuning có thể cải thiện đáng kể độ chính xác của LLM
• Các mô hình ngôn ngữ lớn (LLM) có khả năng lưu trữ lượng lớn kiến thức thực tế trong quá trình huấn luyện trước, nhưng vẫn thường tạo ra câu trả lời sai lệch, gây ảnh hưởng đến độ tin cậy.
• Các nhà nghiên cứu đã thử nghiệm nhiều phương pháp để cải thiện tính chính xác thực tế của LLM, bao gồm điều chỉnh cơ chế chú ý, sử dụng đầu dò nội bộ không giám sát và phát triển phương pháp để LLM từ chối trả lời các câu hỏi không chắc chắn.
• Nghiên cứu mới từ Đại học Carnegie Mellon và Stanford cho thấy tác động của các ví dụ fine-tuning phụ thuộc rất nhiều vào mức độ mã hóa tốt của các sự kiện trong mô hình được huấn luyện trước.
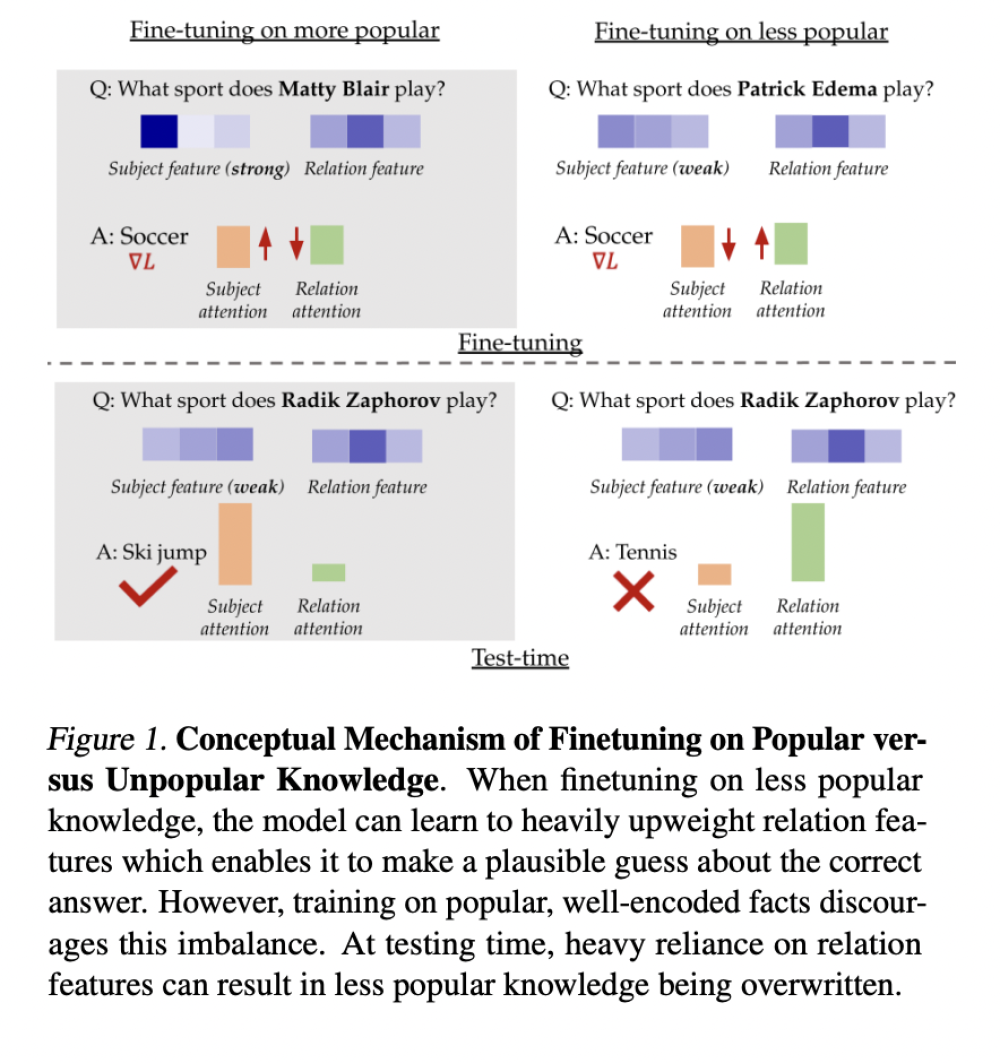
• Fine-tuning trên các sự kiện được mã hóa tốt cải thiện đáng kể tính chính xác thực tế, trong khi sử dụng các sự kiện ít được mã hóa có thể gây hại cho hiệu suất.
• Phương pháp sử dụng một thiết lập tổng hợp để nghiên cứu tác động của dữ liệu fine-tuning đối với tính chính xác thực tế của LLM. Thiết lập này mô phỏng một không gian token đơn giản hóa cho chủ thể, quan hệ và câu trả lời.
• Các phát hiện chính cho thấy fine-tuning các sự kiện phổ biến cải thiện đáng kể tính chính xác thực tế, với các hiệu ứng được khuếch đại đối với các thực thể ít phổ biến hơn.
• Kết quả thực nghiệm trên nhiều bộ dữ liệu (PopQA, Entity-Questions và MMLU) và mô hình (Llama-7B và Mistral) nhất quán cho thấy fine-tuning trên các ví dụ ít phổ biến hoặc ít tự tin hơn kém hiệu quả so với việc sử dụng kiến thức phổ biến.
• Đáng ngạc nhiên, ngay cả các tập con được chọn ngẫu nhiên cũng vượt trội hơn fine-tuning trên kiến thức ít phổ biến nhất, cho thấy việc bao gồm một số sự kiện phổ biến có thể giảm thiểu tác động tiêu cực của những sự kiện ít phổ biến hơn.
• Huấn luyện trên một tập con nhỏ hơn của các sự kiện phổ biến nhất thường hoạt động tương đương hoặc tốt hơn so với việc sử dụng toàn bộ bộ dữ liệu.
• Những phát hiện này chỉ ra rằng việc lựa chọn cẩn thận dữ liệu fine-tuning, tập trung vào các sự kiện nổi tiếng, có thể dẫn đến cải thiện độ chính xác thực tế trong LLM.
• Nghiên cứu mở ra những hướng mới để cải thiện hiệu suất mô hình ngôn ngữ, gợi ý các lợi ích tiềm năng trong kỹ thuật điều chỉnh để khắc phục sự mất cân bằng chú ý, chiến lược học tập theo chương trình và phát triển dữ liệu tổng hợp để trích xuất kiến thức hiệu quả.
📌 Nghiên cứu đột phá cho thấy fine-tuning LLM trên kiến thức phổ biến cải thiện đáng kể độ chính xác. Phát hiện này thách thức cách tiếp cận truyền thống trong thiết kế bộ dữ liệu hỏi đáp và mở ra hướng mới để nâng cao hiệu suất và độ tin cậy của mô hình ngôn ngữ trong nhiều ứng dụng khác nhau.
https://www.marktechpost.com/2024/07/04/rethinking-qa-dataset-design-how-popular-knowledge-enhances-llm-accuracy/



Thảo luận
Follow Us
Tin phổ biến
